3 R 의 자료형 5가지
1. vector : 같은 데이터 타입을 갖는 1차원 배열구조
2. matrix : 같은 데이터 타입을 갖는 2차원 배열구조
3. array : 같은 데이터 타입을 갖는 다차원 구조
4. data frame : 오라클의 테이블, 판다스의 데이터 프레임과 같음
5. list : 서로 다른 데이터 구조인 데이터 타입이 중첩된 구조

4 R 에서의 데이터 검색
emp 데이터 프레임에서 행과 열을 출력하는 문법
R > emp[ 행 검색조건 , 열 ]
( 판다스 > emp[[열]][행 검색 조건]
예제. 특정 컬럼의 데이터 검색하기.
emp[,c("ename","sal")]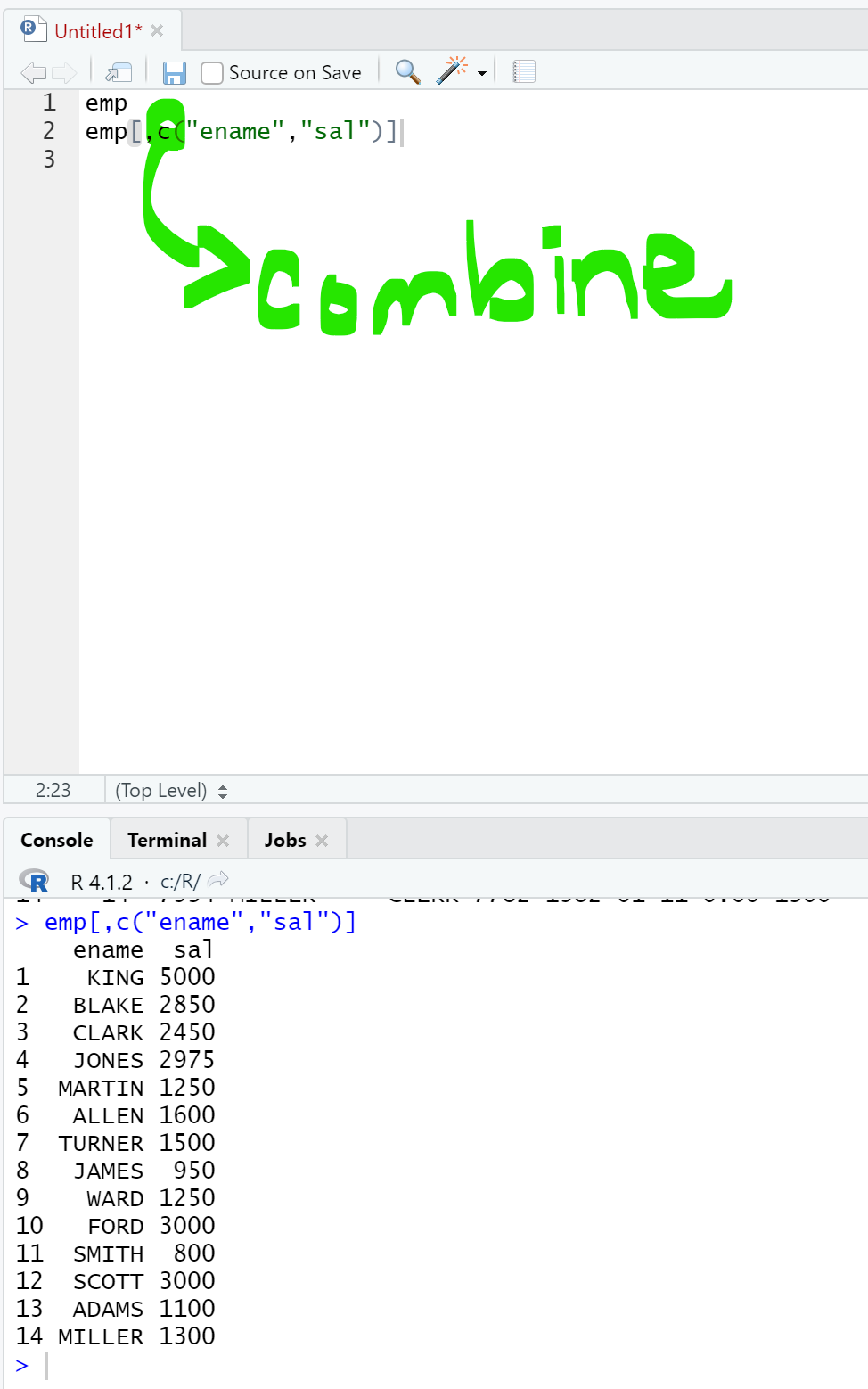
> R은 여러개의 컬럼을 볼 때 c(combine)을 해줘야 볼 수 있음.
예제. 특정 행의 데이터를 검색하기
emp[emp$job == 'SALESMAN', ]> 직업이 'SALESMAN'인 모든 사원들의 컬럼을 출력함
예제. 특정 행의 특정 컬럼만 가져오기
emp[emp$job == 'SALESMAN', c("ename","sal")]> 직업이 'SALESMAN'인 사원들의 이름과 월급 컬럼을 출력함
문제1. 월급이 2000 이상인 사원들의 이름과 월급을 출력하시오.
# 판다스
emp[['ename','sal']][emp.sal >= 2000]# R
emp[emp$sal >= 2000 , c("ename","sal")]문제2. 월급이 3000인 사원들의 이름과 월급을 출력하시오.
# 판다스
emp[['ename','sal']][emp['sal'] == 3000]# R
emp[emp$sal == 3000 , c("ename","sal")]문제3. emp데이터 프레임의 구조를 확인하시오.
# 판다스
emp.info()# R
str(emp)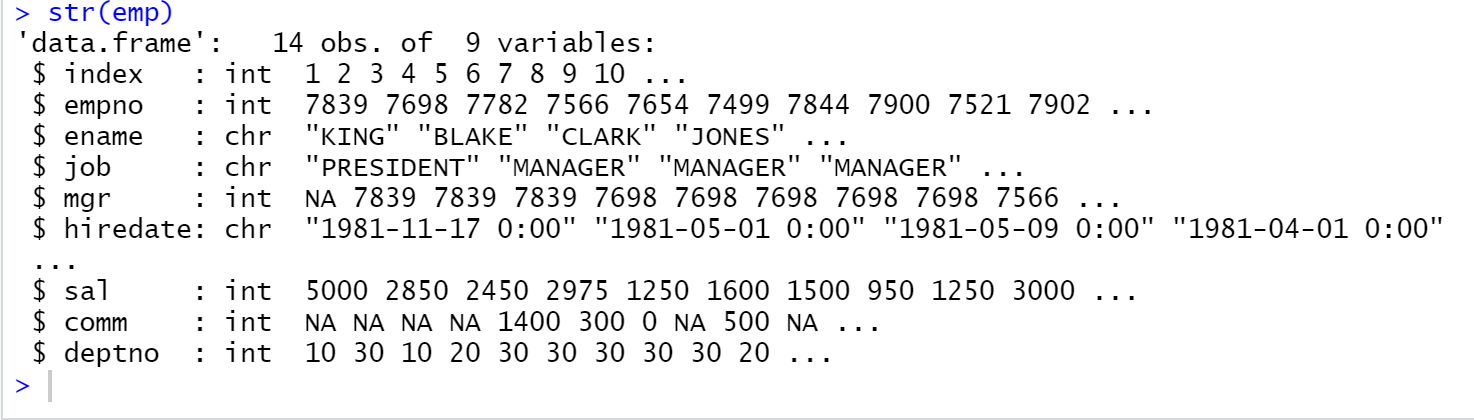
문제4. 입사일이 1981-11-17 0:00 인 사원의 이름과 입사일을 출력하시오.
emp[emp$hiredate == '1981-11-17 0:00', c("ename","hiredate")]hiredate가 문자형(chr)이므로 검색할때 문자 그대로 검색하면 됨
5 R 의 연산자 3가지
1. 산술 연산자 : * / + -
2. 비교 연산자 : >, <, >=, <=, ==, !=
3. 논리 연산자 : &(and, 벡터화 된 연산), &&(and, 벡터화 되지 않은 연산), | (or, 벡터화 된 연산), || (or, 벡터화 되지 않은 연산), ! (not)
ㅇ 벡터(vector) > 같은 데이터 유형을 갖는 1차원 배열구조
# 벡터, 배열형태로 구성됨
x <- c(1,2,3)
x
# 벡터가 아님, 그냥 숫자형 변수
x2 <- 1
x2ㅇ벡터를 이용했을때 논리연산자 &(and) 사용문법
x <- c(1,2,3)
(x > c(1,1,1)) & (x < c(3,3,3))
x 는 (1,2,3)이다. x는 (1,1,1)보다 크고 (3,3,3)보다 작은가?
| x | 1 | 2 | 3 |
| x 는 (1,1,1)보다 크고 (3,3,3)보다 작은가? |
False | True | False |
=> 같은 인덱스에 있는 값들만 연산됨
ㅇ벡터를 이용하지 않았을 때 논리연산자 &&(and) 사용문법
x <- 1
(x > -2) && (x < 2)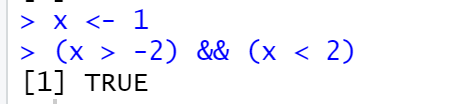
x는 -1이다. x는 -2보다 크고 2보다 작은가? = True
문제5. 직업이 SALESMAN이고 월급이 1200 이상인 사원들의 이름과 월급과 직업을 출력하시오.
# 판다스
emp[['ename','sal']][(emp['job'] == 'SALESMAN')&(emp['sal'] >= 1200)]# R
emp[(emp$job =='SALESMAN')&(emp$sal >= 1200), c("ename","sal","job")]
ㅁ연결 연산자
| 오라클 | 파이썬 | R |
| || | + | paste |
-- SQL
select ename || '의 직업은 ' || job
from emp;# R
paste(emp$ename, '의 직업은 ',emp$job)
R에서 검색하면 위와 같이 정렬되지 않게 나옴 > 오라클이나 판다스처럼 깔끔하게 보려면 다음의 패키지를 설치해야함.
- data.table 패키지 설치
install.packages("data.table")- data.table을 사용하겠다고 지정
library(data.table)패키지만 설치하고 library를 하지 않으면 사용되지 않음(R스튜디오를 킬 때마다 호출해야함)
- data.table을 이용해서 이름과 직업을 다음과 같이 출력
data.table(emp$ename, '의 직업은', emp$job)
문제6. 아래의 SQL을 R로 구현하시오.
-- SQL
select ename || '의 월급은 ' || sal || '입니다'
from emp
where job = 'SALESMAN';# R
# 따로 데이터 뽑은 뒤에 연결연산자 사용
result <- emp[emp$job == 'SALESMAN', c("ename","sal")]
result
result$ename
result$sal
library(data.table) # 데이터 테이블 함수 사용하겠다
data.table(result$ename,'의 월급은 ', result$sal, '입니다.')
문제7. (점심시간 문제) 아래의 SQL을 R로 구현하시오.
-- SQL
select ename || '의 직업은 '|| job || '입니다.'
from emp
where sal >= 3000;# R
result <- emp[emp$sal >= 3000, c("ename", "job")]
library(data.table)
data.table(result$ename, '의 직업은 ',result$job, '입니다.')
ㅇ 기타 비교 연산자
| 오라클 | R |
| in | %in% |
| like | grep |
| is null | is.na |
| between... and | (emp$sal >= 1000) & (emp$sal <= 3000) |
문제8. 직업이 SALESMAN, ANALYST인 사원들의 이름과 월급과 직업을 출력하시오.
# 판다스
emp[['ename','sal','job']][emp['job'].isin(['SALESMAN','ANALYST'])]# R
emp[emp$job %in% c('SALESMAN','ANALYST'), c('ename','sal','job')]> 행 검색조건에 여러개를 넣으려면 combine해줘야함
문제9. 직업이 SALESMAN, ANALYST가 아닌 사람들의 이름과 월급과 직업을 출력하시오.
# 판다스
emp[['ename','sal','job']][~ emp['job'].isin(['SALESMAN','ANALYST'])]
# 판다스는 물결(~)이 아니다 표시# R
emp[!emp$job %in% c('SALESMAN','ANALYST'), c('ename','sal','job')]> 검색조건 맨 앞에 느낌표 !(not) 붙이면 됨
문제10. 부서번호가 10, 20번인 사원들의 이름과 월급과 부서번호를 출력하시오
# 판다스
emp[['ename','sal','deptno']][emp['deptno'].isin([10,20])]# R
emp[emp$deptno %in% c(10,20), c('ename','sal','deptno')]문제11. 커미션이 null인 사원들의 이름과 월급과 커미션을 출력하시오.
# 판다스
emp[['ename','sal','comm']][emp.comm.isnull()]# R
emp[is.na(emp$comm), c('ename','sal','comm')]문제12. 커미션이 null이 아닌 사원들의 이름과 월급과 커미션을 출력하시오.
# 판다스
emp[['ename','sal','comm']][~emp.comm.isnull()]# R
emp[!is.na(emp$comm), c('ename','sal','comm')]
ㅇis.na()라는 함수에 대해서 더 자세히 알아보려면 ? => 아래의 코드를 작성하여 메뉴얼 확인하면 됨
?is.na
문제13. 월급이 1000에서 3000 사이인 사원들의 이름과 월급을 출력하시오.
# 판다스
emp[['ename','sal']][emp.sal.between(1000,3000)]# R
emp[(emp$sal >= 1000)&(emp$sal <= 3000), c('ename','sal') ]문제14. 이름의 첫글자가 A로 시작하는 사원들의 이름과 월급을 출력하시오.
# 판다스
emp[['ename','sal']][emp['ename'].apply(lambda x: x[0] == 'A')]# R
emp[grep("^A", emp$ename),c("ename",'sal')]^ : 시작 ex) ^A = A로 시작하는 것
$ : 끝 ex) A$ = A로 끝나는 것
문제15. 이름의 끝글자가 T로 끝나는 사원들의 이름과 월급을 출력하시오.
# 판다스
emp[['ename','sal']][emp['ename'].apply(lambda x: x[-1] == 'T')]# R
emp[grep("T$", emp$ename),c("ename","sal")]문제16. 이름의 A가 포함된 사원들의 이름과 월급을 출력하시오.
# 판다스
emp[['ename','sal']][emp['ename'].apply(lambda x: 'A' in x)]
#또는
emp[['ename','sal']][emp['ename'].apply(lambda x: x.count('A') >= 1)]# R
emp[grep("A", emp$ename),c("ename","sal")]
# 그냥 A라고만 하면 됨. 와일드카드 붙일 필요 없음문제17. 이름의 두번째 철자가 M인 사원들의 이름을 출력하시오
# 판다스
emp[['ename','sal']][emp['ename'].apply(lambda x: x[1] == 'M')]# R
emp[grep("^.M", emp$ename),c("ename","sal")]R에서 한 자리를 차지하는 와일드카드 문자는 .(점)으로 표기함(오라클의 %와 같은 역할)
^.M = 시작에서 두번째 자리가 M인 것
문제18. 이름의 세번째 철자가 L인 사원들의 이름과 월급을 출력하시오
# 판다스
emp[['ename','sal']][emp['ename'].apply(lambda x: x[2] =='L')]# R
emp[grep("^..L", emp$ename),c("ename","sal")]
6 R 에서의 중복제거
| 오라클 | 판다스 | R |
| distinct | unique | unique |
예제. 부서번호를 출력하는데 중복제거해서 출력하시오.
# R
unique(emp$deptno)# R - 데이터 프레임으로 깔끔하게 보는 방법
library(data.table)
data.table('부서번호' = unique(emp$deptno))
# 판다스
emp.deptno.unique()문제19. 직업이 SALESMAN인 사원들의 부서번호를 출력하는데 중복을 제거해서 출력하시오.
-- SQL
select distinct deptno
from emp
where job == 'SALESMAN';# 판다스
result = emp[['deptno']][emp.job == 'SALESMAN']
result.deptno.unique()# R
result <- emp[emp$job == 'SALESMAN', ]
unique('부서번호' = result$deptno)문제20. 중고차 usedcars.csv에 모델명을 출력하는데 중복제거해서 출력하시오.
cars <- read.csv("c:\\data\\usedcars.csv")
head(cars)
data.table('모델명'=unique(cars$model))
7 R 에서의 데이터 정렬
| 오라클 | R |
| order by | data frame에 내장된 order 옵션 |
| doBy패키지를 설치하고 orderBy 함수를 사용 |
예제. 이름, 월급을 출력하는데 월급이 높은 사원부터 출력되게 하시오.
# R내장함수 order() 사용
emp[order(emp$sal, decreasing = T),c('ename','sal')]
# 패키지 doBy 사용
install.packages("doBy") # 패키지 설치
library(doBy)
orderBy(~ -sal, emp[,c("ename","sal")])= emp[ , c("ename","sal")] 에 대한 출력결과는 orderBy 함수에 넣어 sal을 기준으로 내림차순 정렬하겠다는 의미
~ -sal = sal 내림차순 정렬
~ sal = sal 오름차순 정렬
> 행 조건검색 넣으려면 내장함수 order()보다는 doBy 패키지 이용하는게 더 편함
문제21. 직업이 SALESMAN인 사원들의 이름, 월급, 직업을 출력하는데 월급이 낮은 사원부터 높은 사원순으로 출력하시오.
# 판다스
emp[['ename','sal','job']][emp['job'] == 'SALESMAN'].sort_values(by = 'sal', ascending = True)# R
library(doBy)
orderBy(~ sal, emp[emp$job =='SALESMAN',c("ename","sal", "job")])문제22. 직업이 ANALYST가 아닌 사원들의 이름, 월급, 직업을 출력하는데 월급이 높은 사원부터 출력되게 하시오.
# 판다스
emp[['ename','sal','job']][emp['job'] != 'ANALYST'].sort_values(by = 'sal', ascending = False)# R
library(doBy)
orderBy(~ -sal, emp[emp$job !='ANALYST',c("ename","sal", "job")])문제23. 살인이 일어나는 장소와 건수를 출력하는데 건수가 높은것부터 출력하시오.
# R
crime <- read.csv("c:\\data\\crime_loc.csv") # 로드
head(crime) # 컬럼명 확인 및 데이터 확인
crime[crime$범죄 == '살인', c('장소', '건수')]
library(doBy)
orderBy(~ -건수, crime[crime$범죄 == '살인', c('장소', '건수')]) # 정렬조건식을 result라는 변수에 담아서 orderBy(~ -건수, result) 이렇게 작성해도 가능함.
# 판다스
import pandas as pd
crime <- pd.read_csv("c:\\data\\crime_loc.csv", encoding = 'euckr')
crime[['장소', '건수']][crime.범죄 == '살인'].sort_values(by = '건수', ascending = False)
8 R 에서의 문자함수
| 오라클 | R |
| upper | toupper |
| lower | tolower |
| substr | substr |
| replace | gsub |
예제. 이름과 직업을 출력하는데 전부 소문자로 출력하시오.
library(data.table)
data.table(이름 = tolower(emp$ename), 직업 = tolower(emp$job) )문제24. 월급이 1200 이상인 사원들의 이름, 월급, 직업을 출력하는데 모두 소문자로 출력하시오.
# 판다스
emp[['ename', 'sal','job']][emp.sal >= 1200]
pd.concat([emp.ename.str.lower(), emp.sal, emp.job.str.lower()], axis = 1)# R
library(data.table)
result <- emp[emp$sal >= 1200, c('ename', 'sal','job')]
data.table(이름 = tolower(result$ename), 월급 = tolower(result$sal), 직업 = tolower(result$job))문제25. 아래의 SQL을 R로 구현하시오.
-- SQL
select ename, substr(ename, 1, 3)
from emp;# R
library(data.table)
data.table(이름 = emp$ename, 별칭 = substr(emp$ename, 1,3))R은 substr(컬럼, 시작 인덱스 번호, 끝 인덱스 번호) 인데, Oracle은 substr(컬럼, 시작인덱스, 시작인덱스로부터 가져올 갯수) 임.
즉, Oracle은 1번자리 부터 시작해서 3개의 철자를 가져온다는 뜻이고, R은 1번자리부터 3번자리까지 가져온다는 뜻
문제26. 이름의 첫 철자가 S로 시작하는 사원들의 이름을 출력하시오.
# 판다스
emp[['ename']][emp.ename.apply(lambda x: x[0] == 'S')]# R
library(data.table)
a <- emp[substr(emp$ename,1,1) == 'S', c('ename')]
data.table(a)
문제27. (오늘의 마지막 문제) 우리반 테이블 데이터를 R로 로드해서 성씨가 김씨인 학생의 이름과 나이를 출력하시오.
emp14 <- read.csv("c:\\data\\emp14.csv", encoding = "UTF-8")
emp14
emp14[substr(emp14$ename,1,1) == '김', c('ename','age')]
'Study > class note' 카테고리의 다른 글
| R / 그룹함수, aggregate, tapply, table, format (0) | 2022.01.19 |
|---|---|
| R / 문자함수(gsub), 날짜함수, 변환함수, 일반함수, 그룹함수 (0) | 2022.01.18 |
| R / R설치 및 R이란 무엇인가 (0) | 2022.01.17 |
| python / 상관관계그래프, 신뢰구간그래프 (도박사 이야기) (0) | 2022.01.13 |
| python / 산포도그래프, 라인그래프, 박스그래프, 상관계수그래프 (0) | 2022.01.12 |



