ㅁ서브쿼리문을 왜 사용해야하는가
아래의 질문에 대한 답을 하려면 서브쿼리를 알아야함.
"서울시에서 가장 비싼 생필품명과 가격은?"
"우리나라에서 가장 대학등록금이 높은 학교는?"
"우리나라에서 교통사고가 가장 많이 일어나는 지역은?"
"절도가 가장 많이 일어나는 요일은 언제인가?"
ㅁ서브쿼리문의 종류
1. 단일행 서브쿼리 : 서브쿼리에서 메인쿼리로 하나의 행 값이 리턴되는 서브쿼리문
2. 다중행 서브쿼리
3. 다중 컬럼 서브쿼리
문제335. 우리반에서 가장 나이가 어린 학생의 이름, 나이, 통신사를 출력하시오
select ename, age, telecom
from emp14
where age = (select min(age)
from emp14);
문제336. 직업이 SALESMAN인 사원들의 최대월급보다 더 많은 월급을 받는 사원들의 이름, 월급, 직업을 사원 테이블에서 출력하시오
select ename, sal, job
from emp
where sal > ( select max(sal)
from emp
where job = 'SALESMAN' );
072 서브 쿼리 사용하기 2(다중 행 서브쿼리)
문제337. 직업이 SALESMAN인 사원들과 월급이 같은 사원들의 이름, 월급, 직업을 사원 테이블에서 출력하시오
select ename, sal, job
from emp
where sal = ( select sal
from emp
where job = 'SALESMAN' );
/* 에러
오류메시지 : 단일 행 하위 질의에 2개 이상의 행이 리턴되었습니다.
서브쿼리에서 메인쿼리로 리턴된 결과행이 여러개여서 이퀄(=)로는 비교할 수 없기 때문
*/
select ename, sal, job
from emp
where sal in ( select sal
from emp
where job = 'SALESMAN' );
-- 여러개의 값이 서브쿼리에서 메인쿼리로 리턴되는 경우는 in을 사용해야 함 = 다중행 서브쿼리단일행 서브쿼리문에서 사용하는 연산자 : =, <, >, <=, >=, !=, <>, ^=
다중행 서브쿼리문에서 아용하는 연산자 : in, not in, > all, < all, > any, < any
문제338. 30번 부서번호인 사원들과 직업이 같은 사원들의 이름, 월급, 직업을 출력하시오
select ename, sal, job
from emp
where job in ( select job
from emp
where deptno =30 ) ;문제339. 30번 부서번호인 사원들과 직업이 같지 않은 사원들의 이름, 월급, 직업을 출력하시오
select ename, sal, job
from emp
where job not in ( select distinct job
from emp
where deptno =30 ) ;문제340. KING에게 보고하는 사원들의 이름을 출력하시오
(KING의 직속부하인 사원들 = KING의 사원번호를 mgr번호로 가지고 있는 사원들)
select ename
from emp
where mgr = ( select empno
from emp
where ename = 'KING' );
/* 단일행 서브쿼리문인데 =을 사용하지 않고 in을 사용할 경우 오라클이 알아서 in으로 변경함
그러니 이용자 알아서 단일행/다중행 서브쿼리를 적절히 사용하는 것이 좋음 = 검색성능을 위해 */문제341. 직업이 SALESMAN인 사원들중에서 최대월급보다 더 많은 월급을 받는 사원들의 이름, 월급을 출력하시오
select ename, sal
from emp
where sal > ( select max(sal)
from emp
where job = 'SALESMAN' );
-- 만약 최대가 아니라, 그냥 SALESMAN보다 큰 값을 뽑고 싶을 경우,
select ename, sal
from emp
where sal > ( select sal
from emp
where job = 'SALESMAN' );
/* 에러 : 서브쿼리에서 메인쿼리로 여러개의 값들이 리턴되는 다중행 서브쿼리인데, 단일행 연산자를 사용했기 때문
따라서 이럴때는 다중행 서브쿼리 연산자 > all을 사용하면 됨 */
select ename, sal
from emp
where sal > all ( select sal
from emp
where job = 'SALESMAN' );
/* "> all (서브쿼리)" 서브쿼리의 모든 값보다 큰 것을 뜻함 = 가장 큰 값과 비교
즉, 1250/1600/1500/1250 중 1600보다 큰 값들이 출력됨 */
select ename, sal
from emp
where sal > any ( select sal
from emp
where job = 'SALESMAN' );
/* "> any (서브쿼리)" 서브쿼리의 어느 값보다 큰 것을 뜻함 = 가장 작은 값과 비교
즉, 1250/1600/1500/1250 중 1250보다 큰 값들이 출력됨 */
-- 위의 >any를 사용한 SQL을 아래의 SQL과 결과가 동일함
select ename, sal
from emp
where sal > ( select min(sal)
from emp
where job = 'SALESMAN' );문제342. 1981년도에 입사한 사원들중에서 월급이 가장 작은 사원보다 더 많은 월급을 받는 사월들의 이름, 월급을 사원테이블에서 출력하시오
select ename, sal
from emp
where sal > ( select min(sal)
from emp
where to_char(hiredate, 'RRRR') = 1981 ) ;
-- where절에 컬럼을 가공하면 성능이 느려짐
select ename, sal
from emp
where sal > ( select min(sal)
from emp
where hiredate between to_date('1981/01/01','RRRR/MM/DD') and
to_date('1981/12/31','RRRR/MM/DD') + 1 );
-- 컬럼을 가공하지 않는 방법을 사용해야 성능이 빨라짐문제343. 성이 김씨인 학생들과 나이가 같은 학생들의 이름, 나이를 출력하는데 성이 김씨인 학생들은 제외하고 출력하시오.
select ename, age
from emp14
where age in ( select age
from emp14
where ename like '김%' )
and ename not like '김%' ;문제344. 연봉이 26000 이상인 사원들과 직업이 같은 사원들의 이름, 직업을 출력하시오
select ename, job
from emp
where job in (select job
from emp
where sal * 12 >= 26000 ) ;
-- 컬럼을 가공하면 성능이 느려짐
select ename, job
from emp
where job in (select job
from emp
where sal >= 26000 / 12 ) ;
-- 컬럼을 최대한 가공하지 않는 방법문제345. JAMES보다 더 많은 월급을 받는 사원들의 이름, 월급, 입사일을 출력하는데 최근에 입사한 사원부터 출력하시오.
select ename, sal, hiredate
from emp
where sal > ( select sal
from emp
where ename = 'JAMES' )
order by hiredate desc;문제346. 도로교통공단_교통사고다발지역 데이터를 가지고 오라클 데이터베이스에 테이블을 생성하시오.
테이블명 : car_acc_loc
문제347. 사고지역위치명, 발생건수, 순위를 출력하는데 순위가 발생건수가 높은순 순위를 부여하시오
select 사고지역위치명, 발생건수, rank() over (order by 발생건수 desc) 순위
from car_acc_loc;문제348. 사고유형구분을 중복제거해서 출력하시오
select distinct 사고유형구분
from car_acc_loc;문제349. 사고유형구분, 사고지역위치명, 발생건수, 순위를 출력하는데 사고유형구분별로 각각 발생건수가 높은 순으로 순위를 부여하시오
select 사고유형구분, 사고지역위치명, 발생건수, rank() over (partition by 사고유형구분
order by 발생건수 desc) 순위
from car_acc_loc;문제350. 위의 결과에서 사고유형구분별로 1위만 출력하시오
select *
from (
select 사고유형구분, 사고지역위치명, 발생건수,
rank() over (partition by 사고유형구분
order by 발생건수 desc) 순위
from car_acc_loc
)
where 순위 = 1;문제351. (점심시간 문제) 위의 결과를 다시 출력하는데 1위~5위까지 각각 출력되게 하시오.
select *
from (
select 사고유형구분, 사고지역위치명, 발생건수,
dense_rank() over (partition by 사고유형구분
order by 발생건수 desc) 순위
from car_acc_loc
)
where 순위 <= 5;
073 서브 쿼리 사용하기 3(NOT IN)
ㅇ서브쿼리 종류 3가지 연산자
1. 단일행 서브쿼리문에서 사용하는 연산자 : =, <, >, <=, >=, !=, <>, ^=
2. 다중행 서브쿼리문에서 아용하는 연산자 : in, not in, > all, < all, > any, < any
3. 다중 컬럼 서브쿼리 연산자 : in, not in
문제352. KING에게 보고하는 사원들의 이름을 출력하시오
select ename
from emp
where mgr = (select empno
from emp
where ename = 'KING');문제353. 자기 밑에 직속부하가 한명이라도 있는 사원들을 출력하시오 ( 관리자인 사원들의 이름을 출력)
select ename
from emp
where empno in ( select mgr
from emp ) ;
문제354. 관리자가 아닌 사원들의 이름을 출력하시오
select ename
from emp
where empno not in ( select mgr
from emp );
/* 에러
not in을 사용하는 서브쿼리문에서 null값이 하나라도 메인쿼리로 리턴되면
선택된 레코드가 없다고 나오면서 결과가 출력되지 않음
문제353에서 했던 in의 경우는 mgr에 null이 있어도 6명을 출력했음
> where empno in ( select mgr from emp )
= where empno =any (select mgr from emp) 와 같은 뜻
"= any" or로 조건값들이 나열된 것
반면, not in은 !=all과 같음.
where empno != 7566 and empno != 7839 ..... and empno = null 과 같은 결과를 가져옴
따라서 null을 제거해 줘야 함 */
select ename
from emp
where empno not in ( select mgr
from emp
where mgr is not null );
select ename
from emp
where empno not in ( select nvl(mgr,-1)
from emp );
-- nvl사용시 가장 사용하지 않을 법한 숫자 기입

ㅇ not in을 서브쿼리문에서 사용할 때는 반드시 null이 서브쿼리에서 메인쿼리로 리턴되지 않게 해줘야 합니다.
문제355. 우리반 테이블에서 통신사를 출력하는데 telecom_service에 있는 통신사만 출력하시오
select distinct telecom
from emp14
where telecom in ( select telecom
from telecom_service ) ;문제356. 우리반 테이블에서 통신사를 출력하는데 telecom_service에 없는 통신사만 출력하시오
select telecom
from emp14
where telecom not in ( select telecom
from telecom_service
where telecom is not null ) ;
/* 위의 결과는 진짜 데이터가 없기 때문에 출력되지 않은 것
not in을 사용해서 서브쿼리문을 사용할 때 조금이라도 성능을 높이려면
where 절에 null이 리턴되지 않는 조건을 꼭 넣어줘야함 */
다중 컬럼 서브쿼리 연습
부서번호가 30번인 사원들과 월급이 같은 사원들의 이름과 월급, 커미션을 출력하시오
-- 다중행 서브쿼리
select ename, sal, comm
from emp
where sal in (select sal
from emp
where deptno = 30 ) ;부서번호가 30번인 사원들과 월급도 같고, 커미션도 같은 사원들의 이름과 월급, 커미션, 부서번호를 출력하시오
-- non pair wise 방식
select ename, sal, comm, deptno
from emp
where sal in (select sal
from emp
where deptno = 30 )
and comm in (select comm
from emp
where deptno = 30 ) ;
-- 위와 같이 여러개의 컬럼들에 대한 값이 서브쿼리에서 메인쿼리로 리턴이 되면 다중 컬럼 서브쿼리문ㅇ다중 컬럼 서브쿼리문의 종류 2가지
1. non pair wise 방식
2. pair wise 방식
-- pair wise 방식
select ename, sal, comm, deptno
from emp
where (sal, comm) in (select sal, comm
from emp
where deptno = 30 );non pairwise 방식과 pairwise방식이 출력하는 결과는 서로 다름
> non pairwise방식같은 경우는 부서번호 30번인 사원들 중에 월급중에 하나와 커미션중에 하나가 같으면 무조건 출력되는 것이고 pair wise 방식은 부서번호 30번인 사원의 그 월급과 그 커미션을 받는 사원들이어야지만 출력이 되어짐
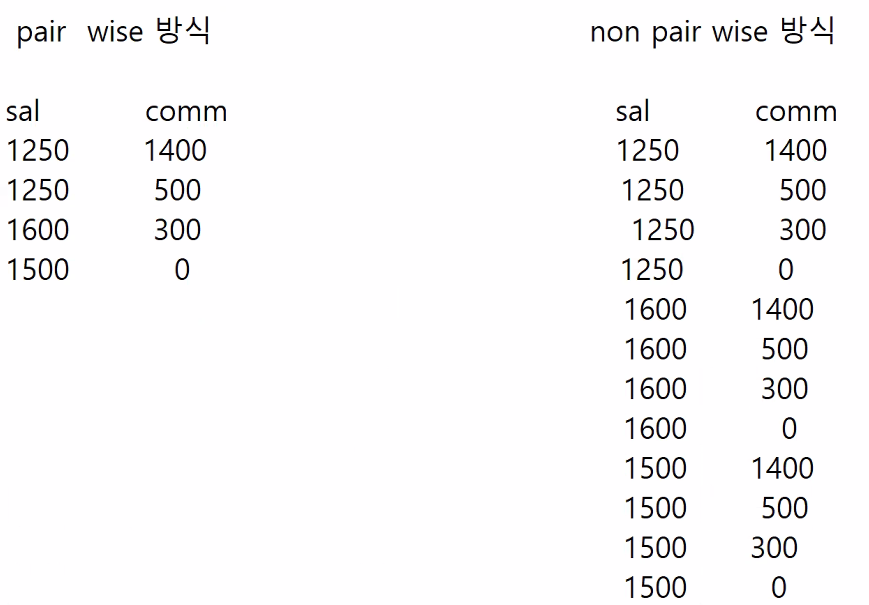

데이터 분석하고자하는 질문을 정확하게 파악해서 거기에 맞는 쿼리문을 작성해줘야함
문제357. 직업이 SALESMAN인 사원들과 월급이 같고 부서번호가 같은 사원들의 이름, 월급, 부서번호를 출력하시오(pairwise 방식)
select ename, sal, deptno
from emp
where (sal, deptno) in ( select sal, deptno
from emp
where job = 'SALESMAN' ) ;
074 서브 쿼리 사용하기 4(EXISTS와 NOT EXISTS)
/* 부서테이블에 존재하는 부서번호 중에서 사원 테이블에도 존재하는 부서번호에 대한 모든 컬럼을 출력하세요
= 부서테이블에서 부서번호, 부서명, 부서위치를 출력하는데 사원테이블에 존재하는 부서번호에 대한 것만 출력하시오 */
-- exists문을 사용하지 않고 수행
select *
from dept
where deptno in ( select deptno
from emp ) ;
/* 만약 서브쿼리의 emp테이블이 10억 건의 대용량 데이터를 구성하고 있다면
10억건의 부서번호를 다 출력해서 메인 쿼리로 리턴을 해줘야 함 > 성능이 느려짐
즉, 서브쿼리 emp 테이블의 크기가 증가할수록 성능이 느려짐 */
-- exists 문으로 수행하면
select *
from dept d
where exists ( select 'X'
from emp e
where e.deptno = d.deptno ) ;
/* exists의 의미 : 존재하는 데이터를 찾는 것
메인쿼리의 테이블d가 서브쿼리로 들어감 = 메인쿼리 먼저 수행되고 서브쿼리가 수행됨
dept 테이블의 부서번호10을 emp테이블에서 조회하는데, 처음부터 스캔해서 읽다가 10번이 존재하면 바로 멈춤
> 10의 존재여부를 확인했기 때문에 더이상 데이터를 읽지 않고 부서번호 20을 찾으러 넘어감
메인쿼리 테이블의 데이터가 적고 서브쿼리의 데이터가 많을때 유리한 SQL */문제358. telecom_service에서 모든 컬럼의 데이터를 출력하는데 emp14테이블에 존재하는 통신사에 대해서만 출력하시오
select *
from telecom_service t
where exists ( select 'x'
from emp14 e
where e.telecom = t.telecom ) ;
/* 이렇게 작성할 경우 결과값은 같지만 검색속도가 훨씬 느림
select *
from telecom_service
where telecom in (select telecom
from emp14 ) ;
*/문제359. 부서테이블에는 존재하는데 사원 테이블에는 존재하지 않는 부서번호를 출력하시오
select *
from dept d
where not exists ( select 'x'
from emp e
where e.deptno = d.deptno );
/*
select *
from dept d
where exists ( select 'x'
from emp e
where e.deptno != d.deptno );
이 쿼리로 작성할 경우 서브쿼리에서 같지 않은 모든 데이터를 찾다보니 결국엔 모든 데이터를 출력하게 됨
*/
075 서브 쿼리 사용하기 5(HAVING절의 서브 쿼리)
ㅁ select문에서 서브쿼리를 작성할 수 있는 절
select 서브쿼리 가능
from 가능
where 가능
group by 불가능
having 가능
order by 가능
= group by절 빼고 다 가능
문제360. 직업, 직업별 토탈월급을 출력하시오(세로출력)
select job, sum(sal)
from emp
group by job;문제361. 위의 결과를 다시 출력하는데 SALESMAN의 토탈월급보다 더 큰 것만 출력하시오
select job, sum(sal)
from emp
where sum(sal) > ( select sum(sal)
from emp
where job = 'SALESMAN'
group by job)
group by job ;
/* 에러
그룹함수로 조건 주는 절은 where절이 아닌 having절 */
select job, sum(sal)
from emp
group by job
having sum(sal) > ( select sum(sal)
from emp
where job = 'SALESMAN' ) ;문제362. 직업, 직업별 인원수를 출력하는데 직업이 ANALYST인 사원들의 인원수보다 더 많은것만 출력하시오
select job, count(*)
from emp
group by job
having count (*) > ( select count(*)
from emp
where job = 'ANALYST' ) ;
076 서브 쿼리 사용하기 6(FROM절의 서브 쿼리 = In line view )
문제363. 이름, 월급, 순위를 출력하는데 순위는 월급이 높은 순서대로 부여하시오.
select ename, sal, rank() over (order by sal desc) 순위
from emp;문제364. 위의 결과에서 1등만 출력하시오
select *
from (
select ename, sal, rank() over (order by sal desc) 순위
from emp
)
where 순위 = 1;문제365. 범죄발생시간 테이블을 생성하시오!
문제366. unpivot문을 이용해서 컬럼을 데이터로 넣고 살인이 일어나는 시간과 건수를 출력하시오
select *
from crime_time
unpivot ( 건수 for 시간 in (f0t3, f3t6, f6t9,f9t12,f12t15,f15t18,f18t21,f21t24) )
where crime_type = '살인';문제367. 살인이 일어난 시간, 건수와 순위를 출력하시오
select 시간, 건수, rank() over (order by 건수 desc ) 순위
from crime_time
unpivot ( 건수 for 시간 in (f0t3, f3t6, f6t9,f9t12,f12t15,f15t18,f18t21,f21t24) )
where crime_type = '살인';문제368. 방화사건이 가장 많이 일어나는 시간대를 출력하시오
select *
from (
select 시간, 건수, rank() over (order by 건수 desc ) 순위
from crime_time
unpivot ( 건수 for 시간 in (f0t3, f3t6, f6t9,f9t12,f12t15,f15t18,f18t21,f21t24) )
where crime_type = '방화'
)
where 순위 = 1;
문제369. (오늘의 마지막 문제)cancer_type, v_type, person_at_risk, 순위를 출력하는데 cancer_type별로 각각 person_at_rick가 높은 순으로 부여하시오.
select cancer_type, v_type, person_at_risk,
rank() over (partition by cancer_type
order by person_at_risk desc) 순위
from vegan;
'Study > class note' 카테고리의 다른 글
| sql중급 / DML문(insert, update, delete) (0) | 2021.11.17 |
|---|---|
| sql중급 / subquery ( select절) (0) | 2021.11.17 |
| sql중급 / subquery(단일 행) (0) | 2021.11.15 |
| sql중급 / 집합연산자 (0) | 2021.11.15 |
| sql중급 / 1999 ANSI join (0) | 2021.11.15 |