R / 조인(outer join, self join, 조직도 시각화), pivot_table, tapply, 집합연산자
ㅁ 조인문법 복습
| SQL | R | Python |
| equi join | merge | pd.merge |
| non equi join | ||
| outer join | ||
| self join |
문제90. 아래의 SQL을 R과 python으로 구현하시오.
-- SQL
select e.ename, d.loc
from emp e, dept d
where e.deptno (+)= d.deptno ;# R
emp <- read.csv("c:\\data\\emp3.csv")
dept <- read.csv("c:\\data\\dept3.csv")
x <- merge(emp, dept, by = "deptno", all.y = T)
x[ , c("ename", "loc")]all.y = T는 dept테이블 쪽의 데이터가 모두 나오게 하라는 뜻. merge할 때 emp가 x, dept가 y임.
all.x = T 라고 쓴다면 emp테이블의 데이터가 모두 나오게 하라는 뜻
all = T는 emp와 dept 테이블의 데이터가 모두 나오게 하라는 뜻 = full outer join
# python
import pandas as pd
emp = pd.read_csv("c:\\data\\emp2.csv")
dept = pd.read_csv("c:\\data\\dept3.csv")
x = pd.merge(emp, dept, on = "deptno", how ="right")
x.loc[:, ['ename', 'loc']]df.loc[ 검색조건, 보고싶은 컬럼 리스트] = 판다스를 R처럼 검색하는 방법
how = "right"는 dept테이블 쪽의 데이터가 모두 나오게 하라는 뜻
how = "left"는 emp테이블 쪽의 데이터가 모두 나오게 하라는 뜻
how = "outer" emp와 dept테이블의 모든 데이터를 나오게 하라는 뜻 = full outer join
how = "inner"(pd.merge의 default )는 오라클의 equi join과 같음.
문제91. 아래의 SQL을 R과 python으로 구현하시오. (full outer join)
-- SQL
select e.ename, d.loc
from emp e full outer join dept d
on (e.deptno = d.deptno) ;# R
x <- merge(emp, dept, by = "deptno", all = T)
x[ , c("ename", "loc")]# python
x = pd.merge(emp, dept, on = "deptno", how = "outer")
# x.loc[:, ['ename', 'loc']]
x[["ename", "loc"]]
ㅇ 오라클의 self join : 자기 자신의 테이블과 조인하는 조인문법
문제92. 아래의 SQL을 R과 python으로 구현하시오.
" 사원 이름을 출력하고 그 옆에 담당 관리자의 이름을 출력하시오"
-- SQL
select e.ename, m.ename
from emp e, emp m
where e.mgr = m.empno;# R
x <- merge(emp, emp, by.x = "mgr", by.y = "empno")
x [ , c("ename.x", "ename.y")]by.x 와 by.y로 연결컬럼을 조인해줌.
# python
x = pd.merge(emp, emp, left_on = "mgr", right_on = "empno")
x.loc[ :, ['ename_x', 'ename_y']]left_on과 right_on으로 연결컬럼을 조인해줌.
=> 위의 코드로 실행하면 KING이 안나오는데 이건 (full) outer join으로 해주면 됨 !
문제93. 아래의 SQL을 R과 python으로 구현하시오.(self join)
"자신의 직속상사보다 더 많은 월급을 받는 사원들의 이름과 월급, 직속상사의 이름과 월급을 출력하시오."
-- SQL
select e.ename, e.sal, m.ename, m.sal
from emp e, emp m
where e.mgr = m.empno and e.sal > m.sal;# R
x <- merge( emp, emp, by.x = "mgr", by.y = "empno")
x[ x$sal.x > x$sal.y , c("ename.x", "sal.x", "ename.y", "sal.y")]
# 만약 컬럼명 바꾸고 싶다면,
# R
x <- merge( emp, emp, by.x = "mgr", by.y = "empno")
result <- x[ x$sal.x > x$sal.y , c("ename.x", "sal.x", "ename.y", "sal.y")]
colnames(result) <- c('사원 이름','사원 월급','관리자 이름','관리자 월급')
result# python
x = pd.merge(emp, emp, left_on = "mgr", right_on = "empno")
x.loc[ x.sal_x > x.sal_y, ['ename_x','sal_x','ename_y','sal_y']]문제94. 위의 self join한 결과 데이터로 사원이름과 직속상사의 이름을 가지고 사원테이블의 조직도를 그리시오.
# R
x <- merge(emp, emp, by.x = "mgr", by.y = "empno")
a < -x [ , c("ename.x", "ename.y")] # 데이터 검색 후 변수에 담아줘야함
install.packages("igraph") # 그래프를 그리기 위한 패키지 설치
library(igraph)
b <- graph.data.frame(a, directed = T) # a데이터 프레임을 "그래프 그리기 위한 데이터 프레임"으로 변환
plot(b)
문제95. 아래의 non equi join을 R과 파이썬으로 구현하시오.
-- SQL
select e.ename, e.sal, s.grade
from emp e, salgrade s
where e.sal between s.losal and s.hisal;emp 테이블에 salgrade테이블의 연결컬럼은 없으나, emp테이블의 sal컬럼이 salgrade의 losal, hisal 범위에 들어가서 연결이 됨. <= non equi join
R > 조인할 수 없음
python > 조인할 수 없음
non equi join은 SQL에서만 가능함.
※ 이 경우 database와 연동해서 파이썬 또는 R에서 출력하면 됨.
문제96. 부서위치, 부서위치별 토탈월급을 출력하시오.
-- SQL
select d.loc, sum(e.sal)
from emp e full outer join dept d
on (e.deptno = d.deptno)
group by d.loc;full outer join을 이용해서 emp에는 데이터가 없는 Boston 이 출력될 수 있게 함.
# R
x<- merge(emp, dept, by = "deptno", all = T)
result <- aggregate(sal ~ loc, x, sum, na.action = na.pass)
colnames(result) <- c("부서위치", "토탈월급")
resultR에서 aggregate함수는 결측치가 안나오는게 default. 결측치를 같이 보려면 na.action = na.pass를 넣어줘서 Boston을 같이 봐야 함.
# python
x = pd.merge(emp, dept, on = "deptno", how = "outer")
result = x.groupby('loc')['sal'].sum().reset_index()
result.columns = ['부서위치', '토탈월급']
result판다스에서는 outer join만 했다면 groupby에서 모든 데이터가 그대로 출력되므로 별도의 코드를 넣을 필요 없음.
문제97. 부서위치, 부서위치별 인원수를 출력하시오.
-- SQL
select d.loc, count(e.ename) as cnt
from emp e full outer join dept d
on (e.deptno = d.deptno)
group by d.loc;full outer join시 count(*)를 할 경우 행을 카운트 하므로 boston의 경우 한 건이 잡힘. 그래서 count(e.empno)로 해야 boston값이 0으로 잡힘.
# R
x<- merge(emp, dept, by = "deptno", all = T)
result <- aggregate(empno ~ loc, x, length, na.action = na.pass) # aggregate에서 결측치는 안나오는게 default
colnames(result) <- c("부서위치", "토탈월급")
resultR의 경우 all = T 하면 boston이 1로 카운트 됨 따라서 all = T를 merge해서 boston이 아예 출력되지 않게 해야함.
# python
x = pd.merge(emp, dept, on = "deptno", how = "outer")
result = x.groupby('loc')['empno'].count().reset_index()
result.columns = ['부서위치', 'cnt']
result
문제98. 아래의 SQL을 R과 파이썬으로 구현하시오.
-- SQL
select sum(decode(d.loc, 'NEW YORK', e.sal, null) ) as "NEW YORK",
sum(decode(d.loc, 'DALLAS',e.sal, null) ) as DALLAS,
sum(decode(d.loc,'CHICAGO', e.sal, null) ) as CHICAGO
from emp e, dept d
where e.deptno = d.deptno ;# R
x <- merge(emp, dept, by = 'deptno')
tapply(x$sal, x$loc, sum)tapply(값 컬럼, 그룹핑할 컬럼명, 그룹함수)
tapply 함수는 그룹핑할 결과를 가로로 출력해주는 함수
# python
x = pd.merge(emp, dept, on = "deptno", how = "outer")
x.pivot_table(columns = 'loc', values = 'sal', aggfunc = 'sum')문제99. (점심시간 문제) 아래의 SQL을 R과 python으로 구현하시오.
-- SQL
select round(avg(decode(d.dname, 'ACCOUNTING', e.sal, null) )) as ACCOUNTING,
round(avg(decode(d.dname, 'RESEARCH', e.sal, null) )) as RESEARCH,
round(avg(decode(d.dname, 'SALES', e.sal, null) )) as SALES
from emp e, dept d
where e.deptno = d.deptno ;# R
x <- merge(emp, dept, by = 'deptno')
tapply(x$sal, x$dname, mean)# python
x = pd.merge(emp, dept, on = "deptno")
x.pivot_table(columns = 'dname', values = 'sal', aggfunc = 'mean')문제100. 다음의 SQL을 R과 파이썬으로 구현하시오.
-- SQL
select e.job, sum(decode(d.loc, 'NEW YORK', e.sal, null) ) as "NEW YORK",
sum(decode(d.loc, 'DALLAS',e.sal, null) ) as DALLAS,
sum(decode(d.loc,'CHICAGO', e.sal, null) ) as CHICAGO
from emp e, dept d
where e.deptno = d.deptno
group by e.job;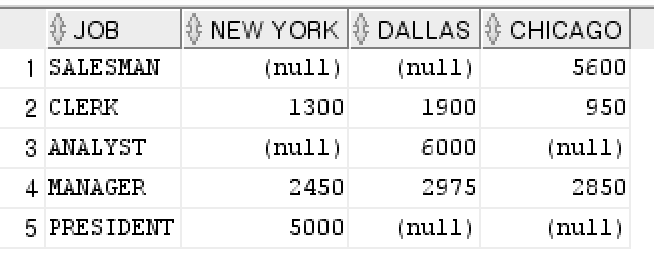
# R
x <- merge(emp, dept, by = 'deptno')
tapply(x$sal, list(x$job, x$loc), sum)# python
x = pd.merge(emp, dept, on = "deptno")
x.pivot_table(columns = 'loc', index = 'job', values = 'sal', aggfunc = 'sum')문제101. 입사년도, 부서위치, 입사년도별 부서위치별 토탈월급을 출력하세요.
-- SQL
select to_char(e.hiredate,'RRRR') as 입사년도, sum(decode(d.loc, 'NEW YORK', e.sal, null) ) as "NEW YORK",
sum(decode(d.loc, 'DALLAS',e.sal, null) ) as DALLAS,
sum(decode(d.loc,'CHICAGO', e.sal, null) ) as CHICAGO
from emp e, dept d
where e.deptno = d.deptno
group by to_char(e.hiredate,'RRRR');
# R
x <- merge(emp, dept, by = 'deptno')
tapply(x$sal, list(format(as.Date(x$hiredate),'%Y'), x$loc), sum)# python
x = pd.merge(emp, dept, on = "deptno")
x['hire_year'] = pd.to_datetime(x.hiredate).dt.year # object인 hiredate를 날짜형으로 변환
x.pivot_table(columns = 'loc', index = 'hire_year', values = 'sal', aggfunc = 'sum')문제102. 위의 결과를 R의 막대 그래프로 시각화하시오.
# R
x <- merge(emp, dept, by = 'deptno')
x2 <- tapply(x$sal, list(format(as.Date(x$hiredate),'%Y'), x$loc), sum)
x2[is.na(x2)] <- 0
barplot(x2, col = rainbow(4), beside = T,legend = rownames(x2),
args.legend = list(x = 'topright',cex = 0.7,bg='transparent'))
# legend를 따로 빼서 써도 됨
# legend ("topright",fill = rainbow(4), legend = rownames(x2), cex = 0.7, bg = 'transparent')
문제103. 위의 막대그래프를 파이썬으로 그리시오.
# python
import pandas as pd
x = pd.merge(emp, dept, on = "deptno")
x['hire_year'] = pd.to_datetime(x.hiredate).dt.year # object인 hiredate를 날짜형으로 변환
a = x.pivot_table(columns = 'loc', index = 'hire_year', values = 'sal', aggfunc = 'sum')
a = a.transpose() # 데이터프레임 행, 열 전환
a.plot(kind = 'bar', figsize =(4,6),rot=False)
17 R 에서의 집합연산자
| SQL | R |
| union all | rbind |
| union | rbind+unique |
| intersect | intersect |
| minus | setdiff |
rbind는 두 개의 결과집합을 위아래로 연결해서 출력하는 함수
cbind는 두개의 결과집합을 양옆으로 연결해서 출력하는 함수
setdiff의 경우 R에 내장되어 있는 setdiff를 사용하면 안되고 dplyr 패키지의 setdiff함수를 사용해야함. 그래야 우리가 원하는 sql의 minus와 같은 결과를 얻을 수 있음.
문제104. 아래의 SQL의 결과를 R로 구현하시오. (union all)
-- SQL
select ename, sal, deptno
from emp
where deptno in (10, 20)
union all
select ename, sal, deptno
from emp
where deptno = 20;union all은 중복을 제거하지 않는 합집합
# R
x1 <- emp[emp$deptno %in% c(10,20), c("ename", "sal","deptno")]
x2 <- emp[emp$deptno == 20, c("ename", "sal","deptno")]
rbind(x1, x2)rbind(x1, x2)은 x1의 결과와 x2의 결과를 위아래로 출력하겠다는 뜻
문제105. 아래의 SQL을 R로 구현하시오.(rollup)
-- SQL
select deptno, sum(sal)
from emp
group by rollup(deptno);
# R
x1 <- aggregate(sal ~ deptno, emp, sum)
x2 <- c(" ",sum(emp$sal)) # 빈셀을 넣기 위해 일부러 null값을 넣음
rbind (x1, x2)
# 컬럼명 변경하려면,
x3 <- rbind (x1, x2)
colnames(x3) <- c("부서번호", "토탈월급")
x3
문제106. 아래의 SQL을 R로 구현하시오. (union)
-- SQL
select ename, sal, deptno
from emp
where deptno in (10,20)
union
select ename, sal, deptno
from emp
where deptno = 10;union은 중복제거가 되는 합집합
# R
x1 <- emp[emp$deptno %in% c(10,20), c("ename", "sal","deptno")]
x2 <- emp[emp$deptno == 10, c("ename", "sal","deptno")]
unique(rbind(x1,x2)) # 중복제거를 위해 unique()를 둘러줌문제107. 아래의 SQL을 R로 구현하시오(minus)
-- SQL
select ename, sal, deptno
from emp
where deptno in (10,20)
minus
select ename, sal, deptno
from emp
where deptno = 10;=> 20번 부서번호에 해당하는 데이터만 출력됨.
# R
install.packages("dplyr") #차집합을 구하기 위한 패키지 설치
library(dplyr)
x1 <- emp[emp$deptno %in% c(10,20), c("ename", "sal","deptno")]
x2 <- emp[emp$deptno == 10, c("ename", "sal","deptno")]
setdiff(x1,x2)R 내장함수에도 setdiff함수가 있고 dplyr 패키지에도 setdiff가 있는데 위의 경우는 dplyr을 라이브러리 했기 때문에 dplyr의 setdiff 함수를 이용하는 것.
문제108. emp200.csv와 emp2.csv를 비교해서 emp200.csv에는 존재하는데 emp2.csv에는 존재하지 않는 데이터를 출력하시오.
# R
emp2 <- read.csv("c:\\data\\emp2.csv")
emp200 <- read.csv("c:\\data\\emp200.csv")
library(dplyr)
setdiff(emp200, emp2)문제109. 아래의 SQL을 R로 구현하시오.(intersect)
-- SQL
select ename, sal, deptno
from emp
where deptno in (10,20)
intersect
select ename, sal, deptno
from emp
where deptno = 10;=> 교집합인 부서번호 10번 데이터만 출력됨
# R
library(dplyr)
x1 <- emp[emp$deptno %in% c(10,20), c("ename", "sal","deptno")]
x2 <- emp[emp$deptno == 10, c("ename", "sal","deptno")]
intersect(x1,x2)
ㅇ nrow함수는 데이터 프레임 행의 갯수를 확인하는 함수
result <- setdiff(emp200, emp2)
nrow(result) # 건수 확인ncol함수는 데이터 프레임의 컬럼의 갯수를 확인하는 함수
문제110. 아래의 SQL을 파이썬으로 구현하시오.
-- SQL
select ename, sal, deptno
from emp
where deptno in (10, 20)
union all
select ename, sal, deptno
from emp
where deptno = 10;# python
x1 = emp[['ename', 'sal', 'deptno']][emp.deptno.isin([10,20])]
x2 = emp[['ename', 'sal', 'deptno']][emp.deptno == 10]
result = pd.concat([x1,x2])
resultpd.concat()이 SQL의 union all 역할을 함.
문제111. 아래의 SQL을 파이썬으로 구현하시오.(rollup)
-- SQL
select deptno, sum(sal)
from emp
group by rollup(deptno);# python
x1 = emp.groupby('deptno')['sal'].sum().reset_index()
x2 = pd.DataFrame( {'deptno' : '토탈값','sal' : emp.sal.sum() }, index = [0])
pd.concat([x1,x2])
# 만약, nan을 넣고 싶다면,
import numpy as np
x2 = pd.DataFrame( {'deptno' : np.nan,'sal' : emp.sal.sum() }, index = [0])
# Series를 씌워서 하는 방법
x1 = emp.groupby('deptno')['sal'].sum().reset_index()
x2 = pd.Series(emp.sal.sum()).reset_index() # 값이 하나만 있을 때 2개의 컬럼을 갖는 데이터 프레임 만들기
x2.columns = ['deptno', 'sal']
pd.concat([x1,x2])문제112. 아래의 SQL을 파이썬으로 구현하시오.(unoin)
-- SQL
select ename, sal, deptno
from emp
where deptno in (10, 20)
union
select ename, sal, deptno
from emp
where deptno = 10;# python
x1 = emp[['ename', 'sal', 'deptno']][emp.deptno.isin([10,20])]
x2 = emp[['ename', 'sal', 'deptno']][emp.deptno == 10]
pd.concat([x1,x2]).drop_duplicates()문제113. 아래의 SQL을 파이썬으로 구현하시오.(minus)
-- SQL
select ename, sal, deptno
from emp
where deptno in (10, 20)
minus
select ename, sal, deptno
from emp
where deptno = 10;# python
x1 = emp[['ename', 'sal', 'deptno']][emp.deptno.isin([10,20])]
x2 = emp[['ename', 'sal', 'deptno']][emp.deptno == 10]
pd.concat([x1,x2]).drop_duplicates(keep = False)문제114. 아래의 SQL을 파이썬으로 구현하시오.(intersect)
-- SQL
select ename, sal, deptno
from emp
where deptno in (10, 20)
intersect
select ename, sal, deptno
from emp
where deptno = 10;# python
x1 = emp[['ename', 'sal', 'deptno']][emp.deptno.isin([10,20])]
x2 = emp[['ename', 'sal', 'deptno']][emp.deptno == 10]
pd.merge(x1,x2)
# pd.concat으로 하는 방법
a = pd.concat([x1,x2])
a[a.duplicated()] # 중복된 데이터만 찾는 것 <= 교집합문제115. emp2.csv와 emp200.csv의 데이터의 차이가 있는지 확인하시오.
# python
emp2 = pd.read_csv("c:\\data\\emp2.csv")
emp200 = pd.read_csv("c:\\data\\emp200.csv")
a = pd.concat([emp2,emp200])
a.drop_duplicates(keep=False)
문제116. (오늘의 마지막 문제) 아래의 SQL을 R과 파이썬으로 구현하시오.
-- SQL
select deptno, sum(sal)
from emp
group by cube(deptno);
# R
x1 <- c("", sum(emp$sal))
x2 <- aggregate(sal ~ deptno, emp, sum)
rbind(x1,x2)# python
import pandas as pd
emp = pd.read_csv("c:\\data\\emp2.csv")
x1 = pd.DataFrame({'deptno': ' ', 'sal' : emp.sal.sum()}, index = [0])
x2 = emp.groupby('deptno')['sal'].sum().reset_index()
pd.concat([x1,x2])