리눅스 / 리눅스의 마리아 디비와 파이썬 연동하기2
30 리눅스의 마리아 디비와 파이썬 연동하기
(리눅스 서버의 인터넷이 켜져있어야함)
1. py389 를 activate 시키고 mysql 모듈을 설치한다.
(base) [oracle@localhost ~]$ conda activate py389
# mysql과 파이썬을 연동하기 위한 패키지를 설치합니다.
(py389) [oracle@localhost ~]$ pip install mysql-connector-python-rf
2. mysql 에 root 유저로 접속해서 모든 ip 의 접속 권한을 scott에게 부여합니다.
# 스위치 유저 - os의 root유저로 접속
(py389) [oracle@localhost ~]$ su -
#mariadb 시작
[root@localhost ~]# systemctl start mariadb
# mysql의 root유저로 접속
[root@localhost ~]# mysql -u root -p
MariaDB [(none)]> use orcl;mysql을 os의 root 유저에서 설치했기 때문에 os의 root로 들어가서 진행하게 됨.
#데이터 베이스에 있는 유저들이 어떤 권한을 가지고 잇는지 확인하는 쿼리
MariaDB [orcl]> select Host,User,plugin,authentication_string FROM mysql.user;
# scott유저에게 데이터베이스에서 할 수 있는 모든 권한을 부여함
MariaDB [orcl]> GRANT ALL PRIVILEGES ON orcl.* to scott@'192.168.122.1';
#권한을 부여하고 다시 확인해보면 됨
MariaDB [orcl]> select Host,User,plugin,authentication_string FROM mysql.user;
MariaDB [orcl]> exit;
Bye
scott으로 접속이 잘 되는지 확인합니다.
[root@localhost ~]# mysql -h 192.168.122.1 -u scott -p
# 접속이 잘 된다면 빠져 나옴
MariaDB [(none)]> exit;
3. mariaDB에 접속하기 위해 방화벽 설정을 합니다.
3306이 현재 mariaDB의 기본포트임.
[root@localhost ~]# firewall-cmd --list-all-zones
[root@localhost ~]# firewall-cmd --permanent --zone=public --add-port=3306/tcp
다시 oracle 유저로 돌아옵니다.
[root@localhost ~]# exit;
logout
(py389) [oracle@localhost ~]$ whoami
oracle
4. 다시 oracle유저로 로그인하여 주피터 노트북을 실행해서 아래의 코드를 실행합니다.
먼저 모바텀의 oracle 유저로 로그인해서 X server를 켭니다.

다시 putty로 돌아와 아래의 명령어를 쳐서 주피터 노트북을 실행시킵니다.
이때 IP주소는 본인의 IP주소로 사용해야합니다.(cmd창 -> ipconfig를 통해 확인)
(py389) [oracle@localhost ~]$ export DISPLAY=172.30.1.38:0.0
(py389) [oracle@localhost ~]$ jupyter notebook
주피터 노트북에 아래의 코드를 입력하여 실행합니다.
import mysql.connector
config = {
"user": "scott",
"password": "tiger",
"host": "192.168.122.1", #local
"database": "orcl", #Database name
"port": "3306" #port는 최초 설치 시 입력한 값(기본값은 3306)
}
conn = mysql.connector.connect(**config)
# db select, insert, update, delete 작업 객체
cursor = conn.cursor()
# 실행할 select 문 구성
sql = "SELECT * FROM emp ORDER BY 1 DESC"
# cursor 객체를 이용해서 수행한다.
cursor.execute(sql)
# select 된 결과 셋 얻어오기
rows= cursor.fetchall() # tuple 이 들어있는 list
print(rows)
위처럼 출력결과가 나온다면 연동이 잘 된 것.
데이터베이스에 있는 emp 테이블의 데이터를 불러온 것. (리눅스 os 에 있는 emp테이블이 아님)
+) 위의 코드 설명
| import mysql.connector # mariadb와 파이썬을 연동하기 위한 모듈 import #데이터베이스 접속정보를 다음과 같이 기술하여 config 변수에 넣음 config = { "user": "scott", "password": "tiger", "host": "192.168.122.1", #local "database": "orcl", #Database name "port": "3306" #port는 최초 설치 시 입력한 값(기본값은 3306) } # mysql 모듈 connecte 함수에 config접속정보를 넣어 conn이라는 객체 생성 conn = mysql.connector.connect(**config) # sql을 실행해서 출력되는 결과를 담을 메모리 공간의 이름을 cursor라고 함 cursor = conn.cursor() # 실행할 select 문 구성 sql = "SELECT * FROM emp ORDER BY 1 DESC" # sql 변수에 담긴 쿼리를 실행해서 실행된 결과를 cursor에 담음 cursor.execute(sql) # cursor에 있는 결과 데이터를 rows 변수에 담습니다 rows= cursor.fetchall() # 데이터를 담은 데이터 구조는 tuple입니다. 튜플을 리스트로 담습니다. print(rows) |
문제169. 위에서 출력된 결과를 판다스의 데이터프레임으로 생성하시오.
import pandas as pd
colname = cursor.description # cursor에 담긴 컬럼정보를 가져와서 colname에 넣습니다.
col = [i[0].lower() for i in colname] #컬럼명 추출
print(col)
emp = pd.DataFrame(rows, columns = col)
emp
문제170. mariaDB와 연동해서 만든 emp 데이터 프레임에는 allen의 정보가 없습니다. 이는 mariaDB의 scott유저의 emp테이블에 allen이 없기 때문입니다.
실제로 없는지 mariaDB에 scott으로 접속해서 sql로 확인해보세요.
[root@localhost ~]# mysql -h 192.168.122.1 -u scott -p
MariaDB [(none)]> use orcl;
MariaDB [orcl]> select count(*) from emp;
MariaDB [orcl]> select * from emp where ename = 'allen';
문제171. emp 테이블에 allen의 데이터를 아래와 같이 insert하시오.
MariaDB [orcl]> insert into emp
-> values(7499,'ALLEN','SALESMAN',7698,'81-02-11',1600,300,30);
MariaDB [orcl]> commit;
문제172. 주피터 노트북에서 다시 mariaDB에 있는 scott의 emp 테이블 데이터를 불러와서 emp 데이터프레임을 다시 만드시오.
처음 연동했던 코드부터 다시 쳐서 emp 테이블 조회하면 업데이트 되어 있음



문제173. mariaDB에서 KING의 월급을 9500으로 update하시오.
MariaDB [orcl]> update emp set sal = 9500 where ename = 'king';
MariaDB [orcl]> commit; # mariadb는 자동커밋되긴 함
문제174. mariaDB와 연동한 파이썬 주피터 노트북에서 emp데이터 프레임을 보고 KING월급이 변경되었는지 확인하시오.
연동쿼리를 다시 실행하고 emp 테이블을 조회해보면 update한 결과가 반영되어 있는 것을 확인할 수 있음.

문제175. (SQL문제) mariaDB에서 SQL로 직업과 직업별 토탈월급을 출력하세요.
MariaDB [orcl]> select job, sum(sal) from emp group by 1 order by 2 desc;mariaDB에서는 group by에 인덱스 조회 가능
문제176. (파이썬 문제) 마리아 디비와 연동한 주피터 노트북에서 사원 데이터 프레임의 월급을 막대 그래프로 시각화하시오.
MariaDB [orcl]> select job, sum(sal) from emp group by 1 with rollup;
문제177. (파이썬 문제) 위의 결과에서 x축에 숫자를 사원이름으로 변경하시오.
result = emp.sal
result.index = emp.ename
result.plot(kind = 'bar', color = 'red')
문제178. (파이썬 문제) 연동하는 파이썬 주피터 노트북에서 직업과 직업별 토탈월급을 출력하시오.
emp.groupby('job')['sal'].sum().reset_index()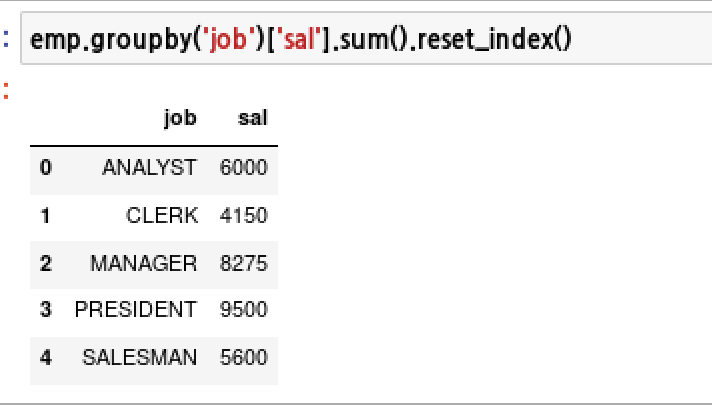
만약 emp 테이블이 대용량 테이블이라고 한다면 select * from emp로 데이터를 다 불러와서 emp 판다스 데이터 프레임을 구성하려면 상당한 메모리 공간도 필요하고 시간도 오래 걸림.
진짜 빅데이터 테이블이면 위와 같은 방법으로 수행하는 것은 비효율적인 방법임.
그래서 연동하는 SQL에서 직업과 직업별 토탈월급을 출력하는 쿼리문으로 작성해서 필요한 데이터만 파이썬으로 가져옵니다.
문제179. (SQL문제) 연동하는 파이썬 코드의 SQL을 직업과 직업별 토탈월급을 출력하는 쿼리로 변경하시오.
import mysql.connector
config = {
"user": "scott",
"password": "tiger",
"host": "192.168.122.1", #local
"database": "orcl", #Database name
"port": "3306" #port는 최초 설치 시 입력한 값(기본값은 3306)
}
conn = mysql.connector.connect(**config)
# db select, insert, update, delete 작업 객체
cursor = conn.cursor()
# 실행할 select 문 구성
sql = """
select job, sum(sal) as sumsal
from emp
group by 1
"""
# cursor 객체를 이용해서 수행한다.
cursor.execute(sql)
# select 된 결과 셋 얻어오기
rows= cursor.fetchall() # tuple 이 들어있는 list
#print(rows)
####################################
import pandas as pd
colname = cursor.description
col = [i[0].lower() for i in colname]
result = pd.DataFrame(rows, columns = col)
result
문제180. (파이썬 문제) 위의 결과를 막대 그래프로 그리시오.
sumsal의 데이터타입이 문자형(object)로 나타나고 있음.

result.sumsal = result.sumsal.astype(int)
result.index = result.job
result.plot(kind = 'bar')
+) 파이썬 데이터프레임 행을 인덱스로 설정하는 방법
result.set_index(['job'], inplace = True)
result
문제181. (SQL문제) database 소프트웨어가 잘하는 것은 대용량 데이터 검색을 빠르게 할 수 있다는 것. 파이썬의 판다스에서 구현하지 못하는 데이터베이스의 인덱스(index)가 있습니다.
인덱스를 이용하게 되면 full table scan 하지 않고 index를 통해서 빠르게 데이터를 검색할 수 있음.
>naver2 테이블에 영화 이름에 인덱스를 생성하시오.
MariaDB [orcl]> create index nr_cname
-> on naver2(cname);
인덱스 잘 만들어졌는지 확인!
MariaDB [orcl]> show index from naver2;
문제182. (SQL문제) 영화이름이 모가디슈인 데이터의 건수를 출력하시오.
MariaDB [orcl]> select count(*) from naver2 where cname = '모가디슈';
현재 cname에 인덱스가 걸려있으므로 데이터를 빠르게 가져올 수 있음.
문제183. 위의 SQL의 실행계획을 확인하여 FULL TABLE SCAN하지 않고 INDEX SCAN을 했는지 확인하시오.
MariaDB [orcl]> explain select count(*) from naver2 where cname = '모가디슈
실행계획을 보면 key에 nr_cname이 보이고, extra에서 using index를 확인할 수 있음.
즉 인덱스를 이용해 테이블의 데이터를 검색했다는 것을 알 수 있음.
문제184. (파이썬 문제) mariaDB와 연동되어 있는 주피터노트북에 naver2 데이터를 불러와 판다스 데이터프레임으로 생성하시오.
import mysql.connector
config = {
"user": "scott",
"password": "tiger",
"host": "192.168.122.1", #local
"database": "orcl", #Database name
"port": "3306" #port는 최초 설치 시 입력한 값(기본값은 3306)
}
conn = mysql.connector.connect(**config)
# db select, insert, update, delete 작업 객체
cursor = conn.cursor()
# 실행할 select 문 구성
sql = """
select *
from naver2
"""
# cursor 객체를 이용해서 수행한다.
cursor.execute(sql)
# select 된 결과 셋 얻어오기
rows= cursor.fetchall() # tuple 이 들어있는 list
#print(rows)
####################################
import pandas as pd
colname_n = cursor.description
col_n = [i[0].lower() for i in colname_n]
naver2 = pd.DataFrame(rows, columns = col_n)
naver2
문제185. (파이썬 문제) 위의 naver2 데이터프레임에서 영화이름이 모가디슈인 행의 건수를 출력하시오.
naver2[:][naver2.cname == '모가디슈'].count()
파이썬으로 검색이 잘 되긴 하지만, 대용량 데이터일 경우 mariaDB에서 가져올 때 메모리 부족 오류가 날 수 있음.
그러므로 애초에 필요한 데이터만 sql로 잘 선별해서 가져오는 작업이 중요함.
문제186. (파이썬 문제) 영화 모가디슈의 평점(1~10점)을 원형그래프로 시각화하시오.
import mysql.connector
config = {
"user": "scott",
"password": "tiger",
"host": "192.168.122.1", #local
"database": "orcl", #Database name
"port": "3306" #port는 최초 설치 시 입력한 값(기본값은 3306)
}
conn = mysql.connector.connect(**config)
# db select, insert, update, delete 작업 객체
cursor = conn.cursor()
# 실행할 select 문 구성
sql = """
select *
from naver2
where cname = '모가디슈'
"""
# cursor 객체를 이용해서 수행한다.
cursor.execute(sql)
# select 된 결과 셋 얻어오기
rows= cursor.fetchall() # tuple 이 들어있는 list
#print(rows)
####################################
import pandas as pd
colname_n = cursor.description
col_n = [i[0].lower() for i in colname_n]
moga = pd.DataFrame(rows, columns = col_n)
moga
#####################################
moga2 = moga.groupby('score')['review'].count().reset_index()
moga2.review = moga2.review.astype(int)
moga2.set_index(['score'], inplace = True)
moga2['review'].plot(kind = 'pie')