하둡 / 스파크 설명, 스파크 설치
ㅇ복습
1. 리눅스 설치
2. 리눅스 기본 명령어
3. vi편집기 명령어
4. 마리아 디비 설치(SQL)
5. 아나콘다 설치
6. 하둡 설치
7. 하이브 설치
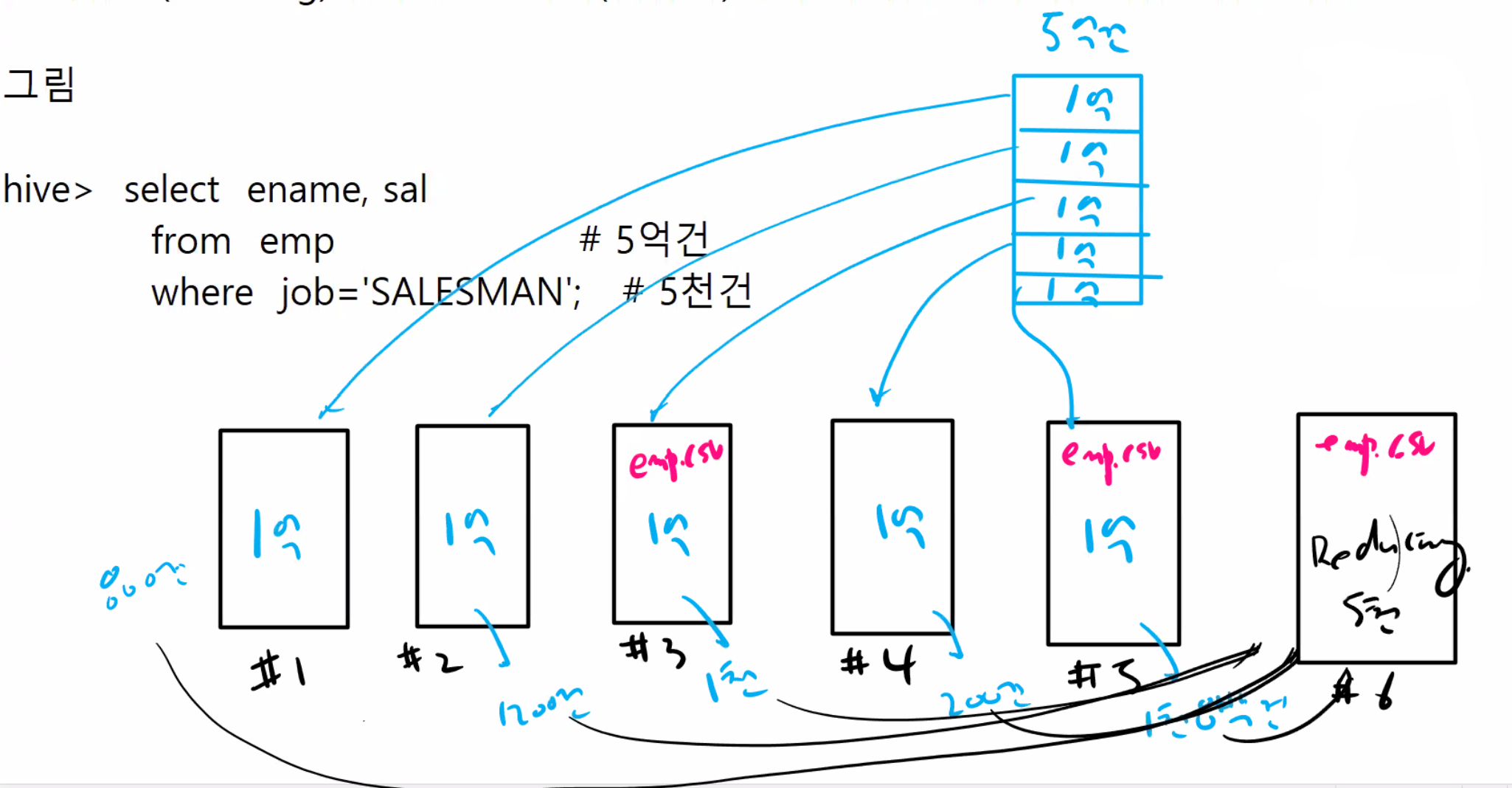
oracle, mysql, mariadb -> 정형화된 데이터
하둡, 하이브, 스파크 -> 비정형화된 데이터
데이터전처리 -> 테이블 생성 -> 시각화 -> 분석결과 해석
문제해결 경험들이 중요함.
45 스파크란 무엇인가?

ㅇ스파크(spark)란?
하둡의 단점을 개선하기 위해 나온 소프트웨어인데 하둡의 단점이 디스크(disk)에서 데이터를 처리하기 때문에 속도가 느림. 그래서 스파크는 메모리(memory)에서 데이터를 처리합니다.(속도가 아주 빠름)
ㅇ하둡의 핵심 엔진 2가지
1. 하둡 파일 시스템(hdfs)
2. 맵리듀싱
ㅇ하둡의 맵리듀싱?
매핑(mapping) 함수 : 검색해야할 데이터를 여러 서버에 분배해주는 역할
리듀싱(reducing) 함수 : 각 서버(컴퓨터)에서 처리한 데이터를 취합하는 역할
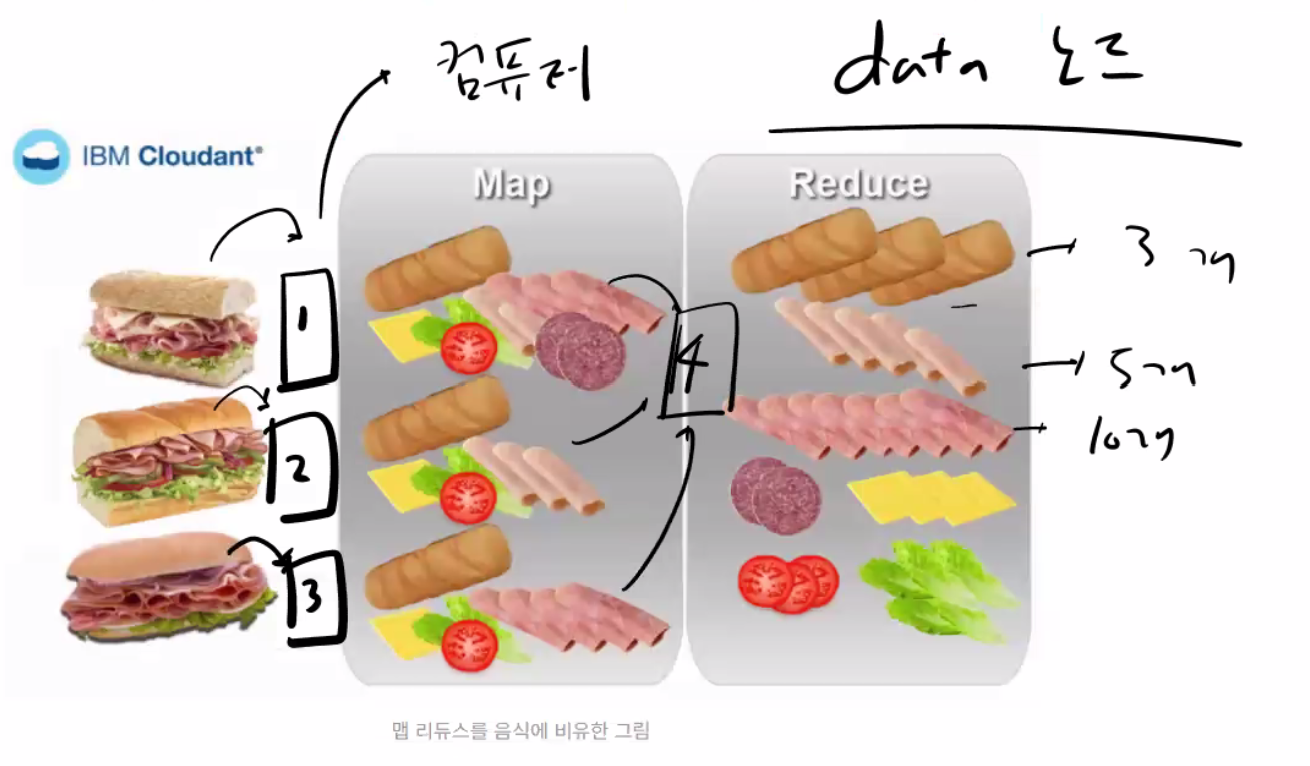
46 스파크 설치
우선 putty에서 oracle로 로그인해서 하둡을 올립니다.(start-all.sh)
(base) [oracle@centos ~]$ jps
3573 Jps : jps 명령어를 수행한 프로세서
3343 JobTracker : 하둡 클러스터에 등록된 전체 job의 스케쥴링을 관리하고 모니터링하는 프로세서
3252 SecondaryNameNode : 하둡 네임노드의 보조 노드에 대한 프로세서로 네임노드의 메타정보(위치정보)를 주기적으로 보조네임노드로 백업하는 역할
3494 TaskTracker : 사용자가 설정한 맵리듀스 프로그램을 실행하는 역할을 하는 프로세서
2939 NameNode : 데이터의 위치정보를 가지고 있는 노드의 프로세서
3094 DataNode : 데이터 노드의 프로세서
ㅇ스파크의 특징
1. 스파크만 단독으로 사용가능합니다.
2. 하둡 분산 파일 시스템의 데이터를 스파크로 불러와서 스칼라 쿼리로도 검색 가능합니다.
ㅇ스파크 설치
1. oracle 의 홈디렉토리로 이동합니다.
(base) [oracle@centos ~]$ cd
(base) [oracle@centos ~]$ pwd
/home/oracle
2. 설치 파일을 다운로드 받는다.
(base) [oracle@centos ~]$ wget https://archive.apache.org/dist/spark/spark-2.0.2/spark-2.0.2-bin-hadoop2.7.tgz
3. 압축을 풉니다.
(base) [oracle@centos ~]$ tar xvzf spark-2.0.2-bin-hadoop2.7.tgz
4. 압축을 풀고 생긴 디렉토리의 이름을 spark 로 변경합니다.
(base) [oracle@centos ~]$ mv spark-2.0.2-bin-hadoop2.7 spark
5. .bash_profile 를 열어서 맨 아래에 아래의 export 문을 입력합니다.
(base) [oracle@centos ~]$ vi .bash_profile
##########################################
export PATH=$PATH:/home/oracle/spark/bin:$PATH
##########################################
6. .bash_profile 을 수행합니다.
(base) [oracle@centos ~]$ source .bash_profile
7. spark에서 사용할 employee.txt 를 생성합니다.
(base) [oracle@centos ~]$ vi employee.txt
(base) [oracle@centos ~]$ pwd
/home/oracle
(base) [oracle@centos ~]$ cat employee.txt
1201,satish,25
1202,krishna,28
1203,amith,39
1204,javed,23
1205,prudvi,23
8. spark-shell 로 접속하여 테이블 생성을 하고 select 합니다.
(base) [oracle@centos ~]$ spark-shell
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.2
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) Client VM, Java 1.7.0_60)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
설명: 테이블 생성전에 아래의 명령어를 실행해야 합니다.지금부터 SQL 사용하겠다 라고 지정 합니다.
scala> val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
sqlContext: org.apache.spark.sql.hive.HiveContext = org.apache.spark.sql.hive.HiveContext@1145c68스칼라에서 하이브 sql사용하겠다 선언!
warning 메시지 나오고 별 내용은 없음.
설명: OS 에 저장한 employee.txt 데이터를 저장할 테이블을 생성합니다.
하이브에서 테이블 생성하던 스크립트를 그대로 적어서 테이블 생성하면 됨.
scala> sqlContext.sql("CREATE TABLE IF NOT EXISTS employee (id INT, name STRING, age INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n'")
22/03/28 11:18:11 ERROR ObjectStore: Version information found in metastore differs 0.12.0 from expected schema version 1.2.0. Schema verififcation is disabled hive.metastore.schema.verification so setting version.
res0: org.apache.spark.sql.DataFrame = []ERROR라 떴지만, 마지막에 res1: org.apache.spark.sql.DataFrame = [] 메시지 떴으면 테이블 생성 된 것.
설명: os 의 employee.txt 파일을 employee 에 로드 합니다.
파일경로 써주지 않아도 데이터 로드 가능
scala> sqlContext.sql("LOAD DATA LOCAL INPATH 'employee.txt' INTO TABLE employee")
res1: org.apache.spark.sql.DataFrame = []
설명: employee 테이블에서 id 와 name과 age 를 조회합니다.
scala> val result = sqlContext.sql("FROM employee SELECT id, name, age")
result: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]val = 변수선언
설명: result 에 입력된 결과를 출력합니다.
scala> result.show()
22/03/28 11:21:25 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
+----+-------+---+
| id| name|age|
+----+-------+---+
|1201| satish| 25|
|1202|krishna| 28|
|1203| amith| 39|
|1204| javed| 23|
|1205| prudvi| 23|
+----+-------+---+
설명: 위에 처럼 result 라는 변수에 담지 않고 바로 sql 을 실행하고 싶다면 아래와 같이 수행하세요 !
scala> sql("select * from employee").show()
+----+-------+---+
| id| name|age|
+----+-------+---+
|1201| satish| 25|
|1202|krishna| 28|
|1203| amith| 39|
|1204| javed| 23|
|1205| prudvi| 23|
+----+-------+---+
문제1. id 가 1202 인 사원의 이름과 나이를 출력하시오 !
scala> sql("select * from employee where id=1202").show()
+----+-------+---+
| id| name|age|
+----+-------+---+
|1202|krishna| 28|
+----+-------+---+
문제2. 이름이 satish 인 사원의 이름과 나이를 출력하시오 !
scala> sql("select * from employee where name='satish'").show()
+----+------+---+
| id| name|age|
+----+------+---+
|1201|satish| 25|
+----+------+---+