
딥러닝 / 손글씨 필기체 인식하는 신경망 만들기
ㅇ 신경망에 들어가는 함수 3가지
1. 활성화 함수 : 은닉층의 뉴런에 들어가는 함수이고 신호를 다음 뉴런으로 보낼때 신호의 정도를 결정하는 함수
- 계단함수, 시그모이드, 렐루, 하이퍼볼릭 탄젠트 함수
2. 출력층 함수 : 은닉층에서 보내온 신호들을 좋바해서 결론을 내주는 함수(확률벡터로 결론을 내줌)
- 소프트맥수(분류용), 항등함수(회귀분석용)
3. 오차함수 : 신경망의 잘못을 깨닫게 해주는 함수
- 크로스엔트로피 함수(분류용), 평균제곱 오차(회귀분석용)
ex. 이미분 분류가 실생활에서 사용되는 예
물품검색대에서 위반 물품 적발, 암여부 악성/양성 판별
11 손글씨 필기체 숫자를 인식하는 신경망 만들기 - p.96

mnist데이터는 숫자 0~9까지의 숫자 이미지로 구성되어 있고 훈련 데이터가 6만장, 테스트 데이터가 1만장으로 구성되어 있습니다. 28x28 크기의 회색조 이미지(1채널)이며 각 픽셀은 0 ~ 255까지의 값을 취합니다.
ㅇ필기체 데이터를 주피터 노트북으로 로드하는 방법
1. 실습 폴더 안에 dataset이라는 폴더를 복사해 주피터 노트북의 작업 디렉토리에 가져다 둡니다.
!dir #홈디렉토리 위치2. 주피터 노트북에서 mnist 데이터를 불러오는 코드를 작성합니다.
import sys, os
sys.path.append(os.pardir) # os의 디렉토리를 파이썬에서 인식하려고 필요한 코드
from dataset.mnist import load_mnist # dataset안에 mnist를 불러와라(홈디렉에 가져다 놓음)
# (훈련데이터,label),(테스트데이터, label)
# flatten : 입력 이미지를 1차원 배열로 만들지 결정하는 파라미터(True:1차원, False:입력이미지 그대로)
# normalize : 0~255로 되어진 이미지의 픽셀값을 0~1 값으로 정규화하는 파라미터(True:정규화,False:정규화안함)
(x_train, t_train),(x_test,t_test) = load_mnist(flatten = True, normalize = False)
print(x_train.shape) #(60000, 784) 데이터 6만개, 28x28 flatten 시켜서 784개의 1차원 배열로 변환함.
문제35. 테스트 데이터는 전체 몇장인지 확인하시오.
print(x_test.shape) #(10000, 784)
문제36. mnist데이터를 flatten시키지 않고(False) 불러와서 훈련데이터의 shape를 출력해보시오.
(x_train, t_train),(x_test,t_test) = load_mnist(flatten = False, normalize = False)
print(x_train.shape) #(60000, 1, 28, 28) 1x28x28로 불러와짐
#(데이터 개수, 색조,가로사이즈,세로사이즈)
문제37. 훈련데이터 6만장 중에 첫번째 필기체 숫자가 무엇인지 출력하시오.
print(t_train[0]) #5
문제38. 훈련 데이터 6만장 중에서 첫번째 필기체 숫자가 5가 맞는지 확인하시오.
print(x_train[0])
문제39. 텐서플로우를 이용해서 텐서플로우에 내장된 mnist 데이터를 가져오시오.
(구글의 텐서플로우는 이미 mnist데이터를 내장하고 있음)
from tensorflow.keras.datasets.mnist import load_data
(x_train2, y_train2),(x_test2,y_test2) = load_data('mnist.npz')
print(x_train2.shape) #(60000, 28, 28)flatten하지 않고 그대로 데이터를 가져왔음.
문제40. mnist의 첫번째 훈련 데이터를 시각화하시오.
import matplotlib.pyplot as plt
img = x_train2[9]
plt.figure()
plt.imshow(img, cmap = 'gray') #회색조 gray
문제41. mnist의 10번째 훈련데이터를 시각화 하시오.
import matplotlib.pyplot as plt
img = x_train2[9]
plt.figure()
plt.imshow(img, cmap = 'gray')
12 저자가 만들어온 가중치 피클(pickle) 파일 불러오는 방법
mnist데이터로 신경망을 생성하고 학습시켜서 만들어온 가중치와 바이어스를 불러오는 방법 배우기
예제1. pickle파일 생성하는 예제
import pickle
a = [0.7, 1.4, 3.5] #학습 시켜서 만든 가중치 값
with open("c:\\deep\\a.pkl","wb") as f: #바이너리 파일로 저장
pickle.dump(a,f)
예제2. 피클파일 a.pkl을 파이썬으로 불러오는 예제
with open("c:\\deep\\a.pkl","rb") as f:
data = pickle.load(f)
print(data) #[0.7, 1.4, 3.5]
예제3. 저자가 만든 피클 파일을 파이썬으로 불러오는 예제.(ch03폴더에 피클파일 있음)
sample_weight.pkl을 c:\\deep 밑에 불여넣어 불러오시오.
with open("c:\\deep\\sample_weight.pkl","rb") as f:
data = pickle.load(f)
print(data)
예제4. 위의 가중치 딕셔너리 파일에서 키값만 추출하시오.
with open("c:\\deep\\sample_weight.pkl","rb") as f:
data = pickle.load(f)
print(data.keys()) #dict_keys(['b2', 'W1', 'b1', 'W2', 'W3', 'b3'])가중치 행렬 3개와 바이어스 행렬 3개로 구성되어 있음. 3층 신경망으로 구성했기 때문에 이렇게 3개가 있는것.
예제5. 저자가 만들어온 pickle파일을 우리가 만들 3층 신경망에 쉽게 불러올 수 있도록 함수를 생성하시오.
import pickle
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
print(network.keys()) #dict_keys(['b2', 'W1', 'b1', 'W2', 'W3', 'b3'])
예제6. 저자가 만든 가중치 행렬의 shape가 각각 어떻게 되는지 확인하시오.
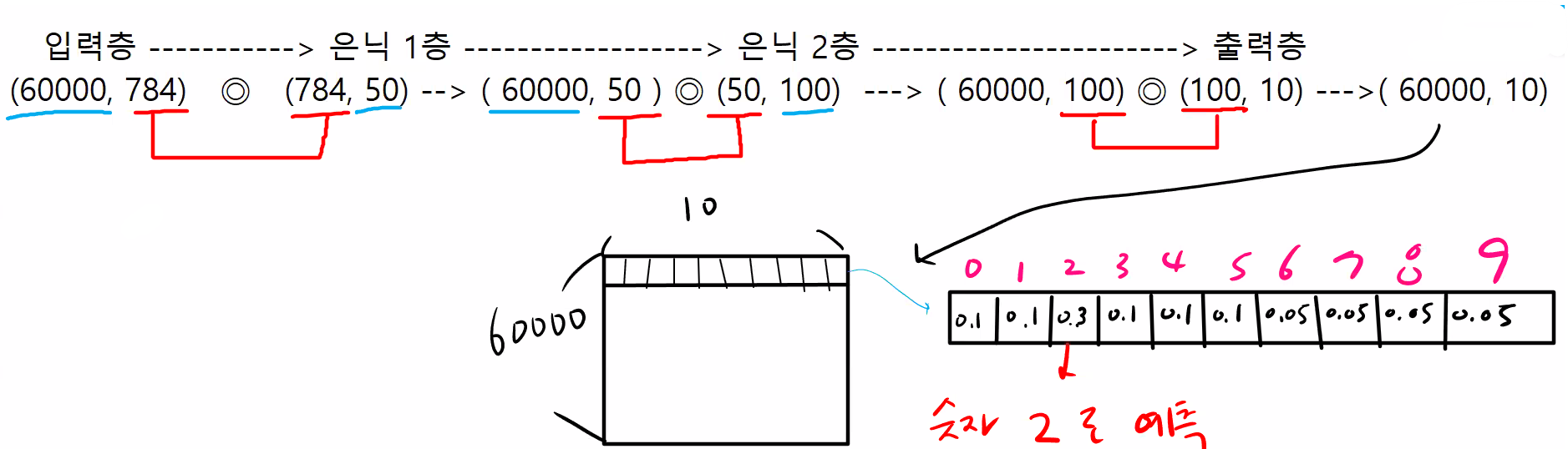
print(network['W1'].shape) #(784, 50)
print(network['W2'].shape) #(50, 100)
print(network['W3'].shape) #(100, 10)
예제7. 위의 가중치 행렬을 보고 저자가 만들어온 신경망의 구조를 그리시오.
예제8. 3층 신경망을 구현하기 위한 첫번째로 저자가 만들어온 가중치와 바이어스를 가져오는 코드를 구현하시오.
import pickle
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
w1, w2, w3 = network['W1'],network['W2'],network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3'] #바이어스
예제9. 위의 코드 아래쪽에 mnist데이터를 불러오는 코드를 추가하시오.
import pickle
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
w1, w2, w3 = network['W1'],network['W2'],network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3'] #바이어스
# mnist데이터를 불러오는 코드 추가
import sys, os
sys.path.append(os.pardir) # os의 디렉토리를 파이썬에서 인식하려고 필요한 코드
from dataset.mnist import load_mnist # dataset안에 mnist를 불러와라(홈디렉에 가져다 놓음)
(x_train, t_train),(x_test,t_test) = load_mnist(flatten = False, normalize = False)
예제10. 3층 신경망중에 입력층을 구성하는데 훈련 데이터 6만개에서 10개의 필기체 데이터만 가져오게 하시오.
import pickle
import sys, os
sys.path.append(os.pardir) # os의 디렉토리를 파이썬에서 인식하려고 필요한 코드
from dataset.mnist import load_mnist # dataset안에 mnist를 불러와라(홈디렉에 가져다 놓음)
#1. 저자가 만든 가중치와 바이어스 불러오기
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
w1, w2, w3 = network['W1'],network['W2'],network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3'] #바이어스
#2. mnist데이터를 불러오기
(x_train, t_train),(x_test,t_test) = load_mnist(flatten = True, normalize = False)
#3. 입력층 구성
x = x_train[0:10] # 일단 10개의 필기체 데이터만 가져옴
print(x)
예제11. 입력 필기체 데이터가 100개가 되게 위의 코드를 구성하시오.
import pickle
import sys, os
sys.path.append(os.pardir) # os의 디렉토리를 파이썬에서 인식하려고 필요한 코드
from dataset.mnist import load_mnist # dataset안에 mnist를 불러와라(홈디렉에 가져다 놓음)
#1. 저자가 만든 가중치와 바이어스 불러오기
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
w1, w2, w3 = network['W1'],network['W2'],network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3'] #바이어스
#2. mnist데이터를 불러오기
(x_train, t_train),(x_test,t_test) = load_mnist(flatten = True, normalize = False)
#3. 입력층 구성
x = x_train[0:100] # 필기체 데이터 100개만 가져오기
print(x.shape) #(100, 784)
예제12. 위의 코드에 은닉1층을 추가하시오.
import numpy as np
import pickle
import sys, os
sys.path.append(os.pardir) # os의 디렉토리를 파이썬에서 인식하려고 필요한 코드
from dataset.mnist import load_mnist # dataset안에 mnist를 불러와라(홈디렉에 가져다 놓음)
#필요 함수
def sigmoid(x):
return 1/(1+np.exp(-x))
#1. 저자가 만든 가중치와 바이어스 불러오기
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
w1, w2, w3 = network['W1'],network['W2'],network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3'] #바이어스
#2. mnist데이터를 불러오기
(x_train, t_train),(x_test,t_test) = load_mnist(flatten = True, normalize = False)
#3. 입력층 구성
x = x_train[0:100] # 필기체 데이터 100개만 가져오기
#4. 은닉 1층
y = np.dot(x,w1) + b1
y_hat = sigmoid(y)
print(y_hat.shape) #(100, 50)
예제13. 이번에는 은닉2층을 구성하시오.

#5. 은닉 2층
z = np.dot(y_hat,w2) + b2
z_hat = sigmoid(z)
print(z_hat.shape) #(100, 100)
예제14. 마지막으로 출력층을 구현하시오.
import numpy as np
import pickle
import sys, os
sys.path.append(os.pardir) # os의 디렉토리를 파이썬에서 인식하려고 필요한 코드
from dataset.mnist import load_mnist # dataset안에 mnist를 불러와라(홈디렉에 가져다 놓음)
#필요 함수
def sigmoid(x):
return 1/(1+np.exp(-x))
def softmax(k):
C = np.max(k)
minus = k - C
np_exp = np.exp(minus)
sum_exp_k = np.sum(np_exp)
y = np_exp / sum_exp_k
return y
#1. 저자가 만든 가중치와 바이어스 불러오기
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
w1, w2, w3 = network['W1'],network['W2'],network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3'] #바이어스
#2. mnist데이터를 불러오기
(x_train, t_train),(x_test,t_test) = load_mnist(flatten = True, normalize = False)
#3. 입력층 구성
x = x_train[0:100] # 필기체 데이터 100개만 가져오기
#4. 은닉 1층
y = np.dot(x,w1) + b1
y_hat = sigmoid(y)
#5. 은닉 2층
z = np.dot(y_hat,w2) + b2
z_hat = sigmoid(z)
#6. 출력층
k = np.dot(z_hat, w3) + b3
k_hat = softmax(k)
print(k_hat.shape) #(100, 10)숫자를 예측하는 10개의 요소로 되어있는 확률벡터 100개가 출력되었습니다.
예제15. 위의 100개의 확률 벡터에서 가장 큰 요소의 인덱스 번호들을 100개 출력하시오.

#7. 확률벡터에서 가장 큰 요소의 인덱스 번호 출력
a = np.argmax(k_hat,axis = 1) #axis=1은 가로 행 요소값 중에 최대요소 인덱스번호 출력
a
예제16. 위의 예측값 100개를 정답과 비교해서 정확도를 확인하시오.
#8. 정확도 비교
b = t_train[0:100] #label
print(sum(a==b)) #96
문제42. 위의 신경망에 훈련데이터 중 20000번째의 숫자를 입력하고 어느 숫자로 예측하는지 확인하시오.
import numpy as np
import pickle
import sys, os
sys.path.append(os.pardir) # os의 디렉토리를 파이썬에서 인식하려고 필요한 코드
from dataset.mnist import load_mnist # dataset안에 mnist를 불러와라(홈디렉에 가져다 놓음)
#필요 함수
def sigmoid(x):
return 1/(1+np.exp(-x))
def softmax(k):
C = np.max(k)
minus = k - C
np_exp = np.exp(minus)
sum_exp_k = np.sum(np_exp)
y = np_exp / sum_exp_k
return y
#1. 저자가 만든 가중치와 바이어스 불러오기
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
w1, w2, w3 = network['W1'],network['W2'],network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3'] #바이어스
#2. mnist데이터를 불러오기
(x_train, t_train),(x_test,t_test) = load_mnist(flatten = True, normalize = False)
#3. 입력층 구성
x = x_train[19999] # 필기체 데이터 100개만 가져오기
#4. 은닉 1층
y = np.dot(x,w1) + b1
y_hat = sigmoid(y)
#5. 은닉 2층
z = np.dot(y_hat,w2) + b2
z_hat = sigmoid(z)
#6. 출력층
k = np.dot(z_hat, w3) + b3
k_hat = softmax(k)
#7. 확률벡터에서 가장 큰 요소의 인덱스 번호 출력
a = np.argmax(k_hat) #axis=1은 가로 행 요소값 중에 최대요소 인덱스번호 출력
a #2
#8. 정확도 비교
b = t_train[19999] #label
print(a==b) #True
13 우리가 직접 만든 필기체를 3층 신경망에 넣고 예측하기
# 필요한 모듈 설치
(base) C:\Users\ejcej>activate snowdeer_env1
(snowdeer_env1) C:\Users\ejcej>pip install opencv-python
1. 필기체 사진을 숫자로 변경하는 방법
import cv2 #이미지 데이터를 전처리하는 모듈
import os #os의 파일들을 인식하기 위한 모듈
path = "c:\\deep\\number2"
file_list = os.listdir(path) #c:\\deep\\ 폴더 안에 있는 파일명들을 file_list변수에 입력
for k in file_list:
print(path+'\\' + k)
img = cv2.imread(path+'\\' + k) #이미지들을 숫자로 변경함
print(img.shape)
#c:\deep\number2\n4_2.png
#(28, 28, 3) 가로픽셀개수, 세로픽셀갯수,색조(컬러)number2 폴더에 이미지1개를 일단 가져옴.
2. 필기체 사진을 28x28 사이즈로 변경하는 방법
# 사이즈 변경하는 코드
import matplotlib.pyplot as plt
for k in file_list: # data100 폴더의 파일을 하나씩 불러옵니다.
img = cv2.imread(path + '\\' + k) # 그 파일을 숫자로 변경합니다.
resize_img = cv2.resize(img, (28 , 28), interpolation=cv2.INTER_CUBIC) # 가로 28, 세로 28로 사이즈 변경
cv2.imwrite('c:\\deep\\test\\' + k, resize_img) # d 드라이브 밑에 resize100 폴더에 저장합니다.
plt.imshow(resize_img)
plt.show()
3. 필기체 사진 흑백처리하는 방법
j= 'c:\\deep\\test\\n4_2.png'
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
def rgb2gray(rgb): # 어떤 컬러 사진이든 제대로 흑백 사진으로 나오게 하기 위해 사용하는 함수
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
img = mpimg.imread(j) # 이미지를 불러와서 숫자로 변경합니다. cv2.imread()랑 같은 메소드
gray = rgb2gray(img) #흑백으로 변경
plt.imshow(gray, cmap = plt.get_cmap('gray')) # 시각화하는 사진을 진짜 흑백 사진으로 변경해서 보여줍니다.
plt.show()
gray.shape #(28, 28)
4. 28x28사이즈를 1x784사이즈로 변경(flatten)하는 방법
x = gray.reshape(1,784)
x.shape
문제44. 입력 데이터 x를 위에서 만들었던 3층 신경망에 넣고 숫자를 예측해보시오.
import numpy as np
import pickle
import sys, os
sys.path.append(os.pardir) # os의 디렉토리를 파이썬에서 인식하려고 필요한 코드
from dataset.mnist import load_mnist # dataset안에 mnist를 불러와라(홈디렉에 가져다 놓음)
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#필요 함수
def sigmoid(x):
return 1/(1+np.exp(-x))
def softmax(k):
C = np.max(k)
minus = k - C
np_exp = np.exp(minus)
sum_exp_k = np.sum(np_exp)
y = np_exp / sum_exp_k
return y
#1. 저자가 만든 가중치와 바이어스 불러오기
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
w1, w2, w3 = network['W1'],network['W2'],network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3'] #바이어스
#2. 입력층 - 이미지 불러오기
j= 'c:\\deep\\test\\n4_2.png'
def rgb2gray(rgb): # 어떤 컬러 사진이든 제대로 흑백 사진으로 나오게 하기 위해 사용하는 함수
return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])
img = mpimg.imread(j) # 이미지를 불러와서 숫자로 변경합니다. cv2.imread()랑 같은 메소드
gray = rgb2gray(img) #흑백으로 변경
plt.imshow(gray, cmap = plt.get_cmap('gray')) # 시각화하는 사진을 진짜 흑백 사진으로 변경해서 보여줍니다.
plt.show()
print(gray.shape) #(1, 28, 28)
x = gray.reshape(1,784)
print(x.shape)
#3. 은닉 1층
y = np.dot(x,w1) + b1
y_hat = sigmoid(y)
#4. 은닉 2층
z = np.dot(y_hat,w2) + b2
z_hat = sigmoid(z)
#5. 출력층
k = np.dot(z_hat, w3) + b3
k_hat = softmax(k)
#7. 확률벡터에서 가장 큰 요소의 인덱스 번호 출력
a = np.argmax(k_hat) #axis=1은 가로 행 요소값 중에 최대요소 인덱스번호 출력
a # 4로 예측됨cv2.imread 함수는 그냥 이미지를 그대로 숫자로 변경하는 함수고,
mpimg.imread 함수는 이미지를 숫자로 변경하는데 흑백으로 다 변경해서 숫자로 변경하는 함수.(따라서 mpimg는 흑백처리를 하지 않아도 됨)
문제45. 아래의 이미지를 3층 신경망에 넣고 2를 잘 예측하는지 출력하시오.
import numpy as np
import pickle
import sys, os
sys.path.append(os.pardir) # os의 디렉토리를 파이썬에서 인식하려고 필요한 코드
from dataset.mnist import load_mnist # dataset안에 mnist를 불러와라(홈디렉에 가져다 놓음)
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#필요 함수
def sigmoid(x):
return 1/(1+np.exp(-x))
def softmax(k):
C = np.max(k)
minus = k - C
np_exp = np.exp(minus)
sum_exp_k = np.sum(np_exp)
y = np_exp / sum_exp_k
return y
#1. 저자가 만든 가중치와 바이어스 불러오기
def init_network():
with open("c:\\deep\\sample_weight.pkl","rb") as f:
network = pickle.load(f)
return network
network = init_network()
w1, w2, w3 = network['W1'],network['W2'],network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3'] #바이어스
#2. 입력층
j= 'c:\\deep\\number\\n2_1.png'
##### 방법1. cv2.imread(), rgb2gray() 함수 사용
def rgb2gray(rgb): # 흑백변경 함수
return np.dot(rgb[...,:3], [0.299,0.587, 0.114]) # R:0.299, G:0.587, B:0.114
img = cv2.imread(j)
print('img.shape :',img.shape) #img.shape : (28, 28, 3)
gray = rgb2gray(img) #흑백으로 변경
plt.imshow(gray, cmap='gray') #이미지 확인
plt.show()
print("gray.shape :", gray.shape) #(28, 28)
x = gray.reshape(1,784)
##### 방법2. cv2.imread()에서 회색조로 불러오기
img = cv2.imread(j,cv2.IMREAD_GRAYSCALE) # cv2.imread에서 회색조로 불러오기
print('img.shape :',img.shape) #img.shape : (28, 28)
plt.imshow(img, cmap='gray') #이미지 확인
plt.show()
x = img.reshape(1, 784)
##### 방법3. cv2.imread(), cv2.cvtColor() 사용
img = cv2.imread(j)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #BGR을 GRAY로 변경
plt.imshow(img, cmap='gray') #이미지 확인
plt.show()
print('img.shape :',img.shape) #img.shape : (28, 28)
x = img.reshape(1,784)
##### 방법4. mpimg.imread()사용
img = mpimg.imread(j)
print('img.shape :',img.shape) #img.shape : (28,28)
plt.imshow(img, cmap='gray') #이미지 확인
plt.show()
x = img.reshape(1,784)
#3. 은닉 1층
y = np.dot(x,w1) + b1
y_hat = sigmoid(y)
#4. 은닉 2층
z = np.dot(y_hat,w2) + b2
z_hat = sigmoid(z)
#5. 출력층
k = np.dot(z_hat, w3) + b3
k_hat = softmax(k)
#7. 확률벡터에서 가장 큰 요소의 인덱스 번호 출력
a = np.argmax(k_hat)
a| 방법1. cv2.imread(), rgb2gray() 함수 사용 |
방법2. cv2.imread()에서 회색조로 불러오기 |
방법3. cv2.imread(), cv2.cvtColor()로 회색조 변환 |
방법4. mpimg.imread()사용 |
| 2 | 2 | 2 | 7 |
1. mpimg.imread() 와 cv2.imread() 차이
mpimg.imread()의 이미지의 색상값에 따라 불러오고,
cv2.imread()의 default는 BGR(일반적으로 RBG 순서지만 opencv는 BGR순서)로 이미지를 불러옵니다.
2. mpimg.imread()는 이미지를 알아서 구분하기때문에 별도의 option값을 주지않아도 grayscale, RBG, RBGA이미지를 분류합니다.
(M, N) for grayscale images.
(M, N, 3) for RGB images.
(M, N, 4) for RGBA images.
+) mpimg 회색조 변환방법
import PIL
import matplotlib.pyplot as plt
img = PIL.Image.open(j)
gray_img = img.convert("L")
plt.imshow(gray_img, cmap='gray')
https://matplotlib.org/3.5.1/api/_as_gen/matplotlib.pyplot.imread.html
3. cv2.imread()의 default는 BGR로 로드되기 때문에 (M, N, 3)형식으로 출력됩니다.
option값을 지정해주면 option에 color or grayscale로 로드됩니다.
original = cv2.imread(fname, cv2.IMREAD_COLOR) # color 로드 (M, N, 3)으로 출력
gray = cv2.imread(fname, cv2.IMREAD_GRAYSCALE) # grayscale 로드 (M, N)으로 출력
unchange = cv2.imread(fname, cv2.IMREAD_UNCHANGED) #origin 데이터 로드, alpha값까지 읽음.
option값에 3개의 flag대신에 1, 0, -1을 사용해도 됩니다.
https://opencv-python.readthedocs.io/en/latest/doc/01.imageStart/imageStart.html
+) grayscale로 변환했을 때 노랗게 나오는 이유