딥러닝 / 3차원 데이터의 합성곱 연산
convolution(이미지의 특징을 추출하는 역할) ---> pooling(이미지를 선명하게 해주는 역할)
5 3차원 데이터의 합성곱 연산 - p.235
우리가 앞에서 배운 합성곱은 그냥 합성곱이었고 지금부터 배울 합성곱은 3차원 합성곱.
이 세상의 모든 이미지들은 흑백보다는 컬러가 대부분. 컬러 이미지가 red, green, blue로 되어 있기 때문에 3차원.
문제155. 위 그림의 RGB입력 이미지와 RGB필터 이미지를 생성하시오.

import numpy as np
x2 =np.array([[[1,2,3,0],
[0,1,2,3],
[3,0,1,2],
[2,3,0,1]],
[[2,3,4,1],
[1,2,3,4],
[4,1,2,3],
[3,4,1,2]],
[[3,4,5,2],
[2,3,4,5],
[5,2,3,4],
[4,5,2,3]]])
filter2 =np.array([[[2,0,1],
[0,1,2],
[1,0,2]],
[[3,1,2],
[1,2,3],
[2,1,3]],
[[4,2,3],
[2,3,4],
[3,2,4]]])
문제156. 3차원 합성곱을 하기전에 원본 이미지 x2에서 red행렬만 출력하시오.
x2.shape #(3, 4, 4) (채널(색상), 가로, 세로)
print(x2[0,:,:])
# [[1 2 3 0]
# [0 1 2 3]
# [3 0 1 2]
# [2 3 0 1]]
문제157. 출력된 red 행렬에서 아래의 3x3 영역만 출력하시오.
print(x2[0,:3,:3])
# [[1 2 3]
# [0 1 2]
# [3 0 1]]
문제158. 원본 이미지의 red행렬 3x3행렬과 필터 이미지 red행렬 3x3과의 합성곱을 하시오.
x2[0,:3,:3] * filter2[0,:,:]
# array([[2, 0, 3],
# [0, 1, 4],
# [3, 0, 2]])
문제159. 문제 152번 코드를 참조해서 위의 원본이미지에서 Red 행렬만 stride해서 필터와 합성곱을 하시오
a = []
for i in range(2):
for k in range(2):
a.append(np.sum(x2[0,i:i+3,k:k+3]*filter2[0]))
b = np.array(a).reshape(2,2)
b
문제160. 위에는 red행렬에 대한 합성곱 결과를 출력했는데 이번에는 Green 행렬과 blue행렬에 대해서도 합성곱하여 a리스트에 다 담겨서 아래와 같이 출력되게 하시오.
a = []
for j in range(len(x2)):
for i in range(2):
for k in range(2):
a.append(np.sum(x2[j,i:i+3,k:k+3]*filter2[j]))
print(a) #[15, 16, 6, 15, 46, 48, 36, 46, 95, 98, 84, 95]
문제161. 위에서 출력된 a리스트를 numpy로 reshape하는데 3x4행렬로 만드시오.
np.array(a).reshape(3,4)
문제162. 아래의 행렬에서 세로로 값을 더해서 아래의 결과가 출력되게 하시오.
result = np.array(a).reshape(3,4)
np.sum(result, axis = 0) #array([156, 162, 126, 156])
문제163. 위의 결과를 아래와 같이 2x2 행렬로 출력하시오.
np.sum(result, axis = 0).reshape(2,2)
6 스트라이드 - p.233
합성곱을 할 때 원본 이미지를 필터로 이동하면 피처맵을 생성하는 과정을 말함.
즉 이동을 몇 칸으로 할 지 결정하는 것
항상 원본이미지가 합성곱 층을 통과하더라도 작아지지 않고 그냥 원본이미지를 유지하고 싶음.
텐서플로우로 코딩할 때는 스트라이드에 대한 고민을 하지 않아도 되고 패딩을 몇을 줘야할 지 계산하지 않아도 됨.
model.add(Conv2D(100,(3,3), padding = 'same', input_shape = (4,4,3)))=> 필터 갯수 100개, 필터사이즈 (3,3), 출력되는 결과 모양이 원본이미지랑 똑같이 되도록 패딩해라(padding = 'same')
input_shape가 (4,4,3)인 이유는 위의 그림 입력데이터가 4x4행렬의 3채널이기 때문. 만약 mnist 데이터를 넣는다면 (28,28,1)이고 설현 사진을 넣는다면 (32,32,3)이 input_shape가 됨.
ㅇ파이썬 날코딩(p251)
conv_params = {'filter_num':100, 'filter_size':3, 'pad':계산해서 적어야함, 'stride':1}패딩을 계산하려면 책 p234페이지에 나온대로 하면 됨.

OH : 출력 이미지의 세로사이즈
OW : 출력 이미지의 가로사이즈
H : 입력 이미지의 세로
W : 입력 이미지의 가로
FH : 필터의 세로
FW : 필터의 가로

우리는 텐서플로우로 신경망 구성할거니까 아래의 코드만 신경쓰면 되는데 머리속에 아래의 내용이 연상되면 됨.
model.add(Conv2D(100,(3,3), padding = 'same', input_shape = (4,4,3)))컨볼루션층에서 하는 작업은 원본 이미지를 가지고 여러개의 비슷한 이미지를 만들어내는 작업.
이 비슷한 이미지들이 바로 Feature map. 그리고 이 피쳐맵의 갯수는 필터의 갯수와 동일하게 생성됨.
아래와 같이 convolution층을 구성했으면 생성되는 피처맵의 갯수는?
model.add(Conv2D)32, (3,3), padding = 'same', input_shape=(4,4,1)))위의 합성곱층에 입력되는 데이터 100장 --> convolution --> 피처맵의 갯수? = 3200장
문제164. CNN층을 넣지 않은 완전연결계층만 있는 6장까지 구현한 필기체 분류 3층 신경망을 수행하시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense # 완전 연결계층을 구성하기 위한 모듈
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
tf.random.set_seed(777)
(x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # mnist 데이터 로드
# 2. 정규화 진행
x_train = (x_train.reshape((60000, 28 * 28))) / 255
x_test = (x_test.reshape((10000, 28 * 28))) / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Dense(50, activation = 'sigmoid', input_shape = (784, ))) # 1층
model.add(Dense(50, activation = 'sigmoid') ) # 2층 은닉층
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='SGD',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
#6. 모델을 훈련시킵니다.
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7.모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
train_acc_list
test_acc_list=history.history['val_acc']
test_acc_list
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()Epoch 30/30
600/600 [==============================] - 0s 783us/step - loss: 0.4140 - acc: 0.8875 - val_loss: 0.3982 - val_acc: 0.8894
313/313 [==============================] - 0s 725us/step - loss: 0.3982 - acc: 0.8894
문제165. 위에 코드에 convolution층과 pooling층을 넣으시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense # 완전 연결계층을 구성하기 위한 모듈
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
tf.random.set_seed(777)
(x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # mnist 데이터 로드
print(x_train.shape, x_test.shape) #(60000, 28, 28) (10000, 28, 28)필기체 mnist데이터는 색조를 나타내는 차원이 없음.
컨볼루션을 하려면 색조를 넣어줘야함.
그래서 아래와 같이 색조를 나타내는 차원을 추가해줘야함.
(60000,28,28) ---> (60000,28,28,1)
(10000,28,28) ---> (10000,28,28,1)
3차원을 4차원으로 변경해주되 안의 요소(픽셀)의 갯수는 동일해야함.
3차원(60000*28*28)을 4차원(60000*28*28*1)로 갯수는 동일.
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)reshape할 때 -1의 의미는 학습데이터는 갯수만큼 알아서 하고, 4차원으로 변경하기만 해라 라는 뜻.
문제165. 위의 코드에 convolution층과 pooling층을 한 개 넣고 결과 정확도를 출력하시오
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense,Conv2D,MaxPooling2D, Flatten # 완전 연결계층, 합성곱층, pooling층, Flatten
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
tf.random.set_seed(777)
(x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # mnist 데이터 로드
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
# print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)
# 2. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(28,28,1), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
model.add(Flatten()) # 완전연결계층에 들어갈 수 있도록 이미지(피처맵)를 1차원으로 변경해야함
model.add(Dense(50, activation = 'sigmoid', input_shape = (784, ))) # 1층
model.add(Dense(50, activation = 'sigmoid') ) # 2층 은닉층
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='SGD',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
# 6. 모델을 훈련시킵니다.
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7. 모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
train_acc_list
test_acc_list=history.history['val_acc']
test_acc_list
# 8. 시각화
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
cnn 안 썼을 때 훈련데이터 정확도 0.8875, 테스트데이터 정확도 0.8894
cnn 썼을 때 훈련데이터 정확도 0.9424, 테스트데이터 정확도 0.9406
7 블럭으로 생각하기 - p237
블럭으로 생각하기가 필요한 이유?
1. 신경망에서 이미지가 배치단위로 어떻게 흘러가는지 이해하기
2. 합성곱층을 class로 구현하기 위해서
3차원 합성곱 연산은 데이터와 필터를 블럭으로 생각하면 쉽습니다.

RGB컬러 사진 1장을 RGB필터로 합성곱해서 1개의 피처맵(월본 이미지의 특징을 담고 있는 이미지)을 출력하는 그림

사진 1장에 필터 FN개를 합성곱하고 FN개의 피처맵을 출력하는 그림
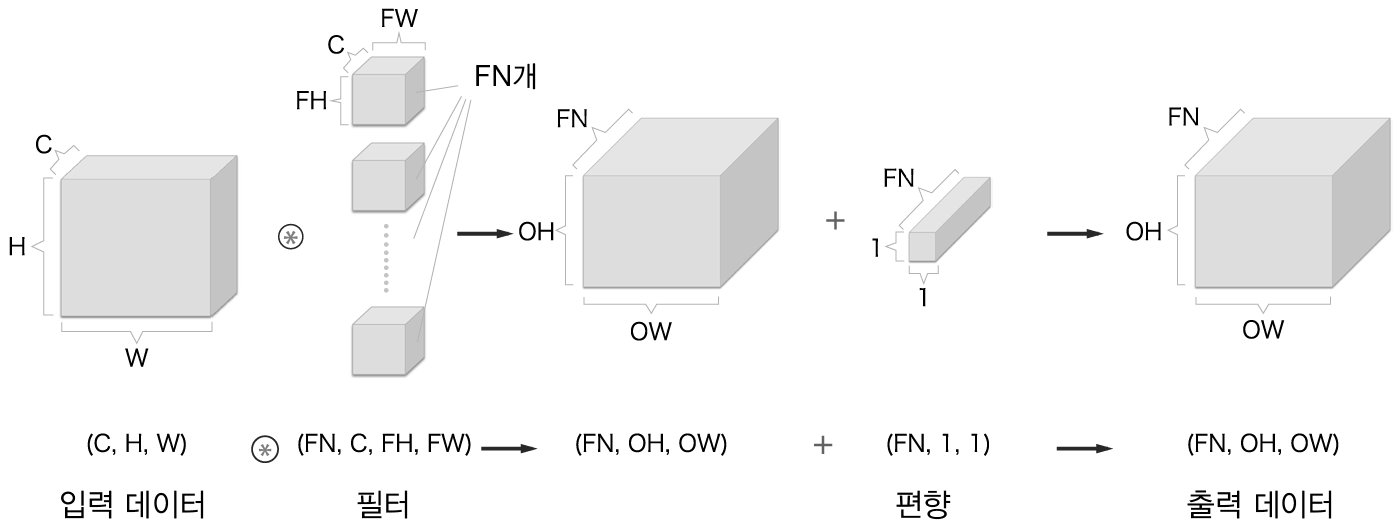
사진1장에 필터 FN개를 합성곱하고 FN의 편향을 더해서 FN개의 피처맵을 출력하는 그림

미니배치의 갯수 N개 만큼 설현 사진을 입력해서 필터 FN개와 합성곱하여 미니배치 갯수 N개만큼 피처맵을 출력하는 그림
정리하면 RGB 사진 1장을 32개의 RGB필터로 합성곱하면 32개의 피처맵이 생기고, 100개의 사진을 32개의 RGB필터와 합성곱하면 사진 1장당 피처맵이 32개, 100장이므로 피처맵 총 3200장 생성.
문재166. 사진 한 장을 4차원 행렬로 만드시오.
import numpy as np
x1 = np.random.rand(1,3,7,7) # 사진 1장, 컬러, 가로 7, 세로 7
print(x1)
print(x1.shape) #(1, 3, 7, 7)
문제167. 사진 10장을 생성하시오.
import numpy as np
x1 = np.random.rand(10,3,7,7) # 사진 10장, 컬러, 가로 7, 세로 7
print(x1.shape) #(10, 3, 7, 7)
이렇게 사진 10장을 만들어봤는데 사진 10장인 4차원의 데이터를 그대로 신경망에 입력하고 합성곱을 하게 되면 시간이 너무 많이 걸림. 그래서 시간을 줄일려면 어떻게 해줘야 할까?
-> im2col 함수를 이용해 4차원 --> 2차원으로 변경해주면 됨
8 im2col 함수 - p243
im2col함수는 신경망에서 합성곱을 진행하는데 입력되는 4차원 데이터를 2차원 데이터로 차원축소해서 2차원 필터와 내적해서 합성곱하게 만드는 함수

(10,3,7,7) ---> (90,75)
4차원 ---> 2차원이 되는 원리

사진 (100,3,7,7)을 (100,147)로 변경한 것
위의 작업이 실제로 합성곱할 때 작업되는 것은 아니고 4차원을 2차원으로 변경하면 이렇더라는 것을 이해하기 위한 설명

(10,3,7,7)을 필터(1,3,5,5)에 맞춰 2차원으로 바꾸면 (90,75)가 됨

필터도 2차원으로 바꾼 뒤, 원본이미지 2차원과 내적시키면 됨.
(90,75) ◎(10,75) => 차원이 맞지 않으므로 필터 (10,75)를 전치시켜 내적시킴
(90,75) ◎(75,10) => (90,10) 내적 후 4차원으로 다시 reshape하면 됨
문제168. 사진 10장을 가로 7, 세로 7, RGB채널로 생성하시오.
import numpy as np
x1 = np.random.rand(10,3,7,7) # 사진 10장, 컬러, 가로 7, 세로 7
print(x1.shape) #(10, 3, 7, 7)
문제169. im2col 함수를 생성하시오.
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
"""다수의 이미지를 입력받아 2차원 배열로 변환한다(평탄화).
Parameters
----------
input_data : 4차원 배열 형태의 입력 데이터(이미지 수, 채널 수, 높이, 너비)
filter_h : 필터의 높이
filter_w : 필터의 너비
stride : 스트라이드
pad : 패딩
Returns
-------
col : 2차원 배열
"""
N, C, H, W = input_data.shape
out_h = (H + 2 * pad - filter_h) // stride + 1
out_w = (W + 2 * pad - filter_w) // stride + 1
img = np.pad(input_data, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride * out_h
for x in range(filter_w):
x_max = x + stride * out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N * out_h * out_w, -1)
return col
문제170. 사진10장을 im2col 함수에 넣어서 2차원 행렬로 변환하시오.
4차원(10,3,7,7) --> 2차원(90,75)
x1 = np.random.rand(10,3,7,7) # 사진 10장, 컬러, 가로 7, 세로 7
result = im2col(x1,5,5, stride = 1, pad = 0) #4차원 --> 2차원으로 변환
print(result.shape) #(90, 75)
문제171. 사진 100장을 im2col 함수에 넣어서 2차원 행렬로 변환하시오. 필터사이즈는 5*5, 스트라이드 1, 패딩 0
x1 = np.random.rand(100,3,7,7) # 사진 100장, 컬러, 가로 7, 세로 7
result = im2col(x1,5,5, stride = 1, pad = 0) #4차원 --> 2차원으로 변환
print(result.shape) #900, 75)
지금까지 원본 이미지만 2차원으로 변경했고 이제 필터도 2차원으로 변경해줘야함
filter2 = np.random.rand(10,3,5,5)
print(filter2.shape) #(10, 3, 5, 5)필터는 im2col을 이용하지 않고 그냥 reshape의 기능만을 이용해서 2차원으로 변경해줌
im2col은 원본이미지를 필터사이즈에 맞춰서 2차원으로 변경시키는 함수지, 필터를 2차원으로 변경시키는 함수가 아님.
문제172. 필터 4차원을 3차원으로 변경하시오.
4차원(10,3,5,5) ---> 3차원(10,3,25)
filter2 = np.random.rand(10,3,5,5)
filter2 = filter2.reshape(10,3,-1) # -1은 이 자리에 뭐가 올지 모르겠지만 알아서 계산해줘라~ 라는 뜻
filter2.shape #(10, 3, 25)
문제173. 아래의 필터 4차원을 2차원으로 변경하시오.
filter2 = np.random.rand(10,3,5,5)
filter2= filter2.reshape(10,3,-1) # -1은 이 자리에 뭐가 올지 모르겠지만 알아서 계산해줘라~ 라는 뜻
filter2.shape #(10, 3, 25)
filter2 = filter2.reshape(10,-1)
filter2.shape #(10, 75)
원본이미지 : (100, 3, 7, 7) ---> (900,75) : im2col로 변환
필터이미지 : (10, 3, 5, 5) ---> (10,75) : reshape로 변환
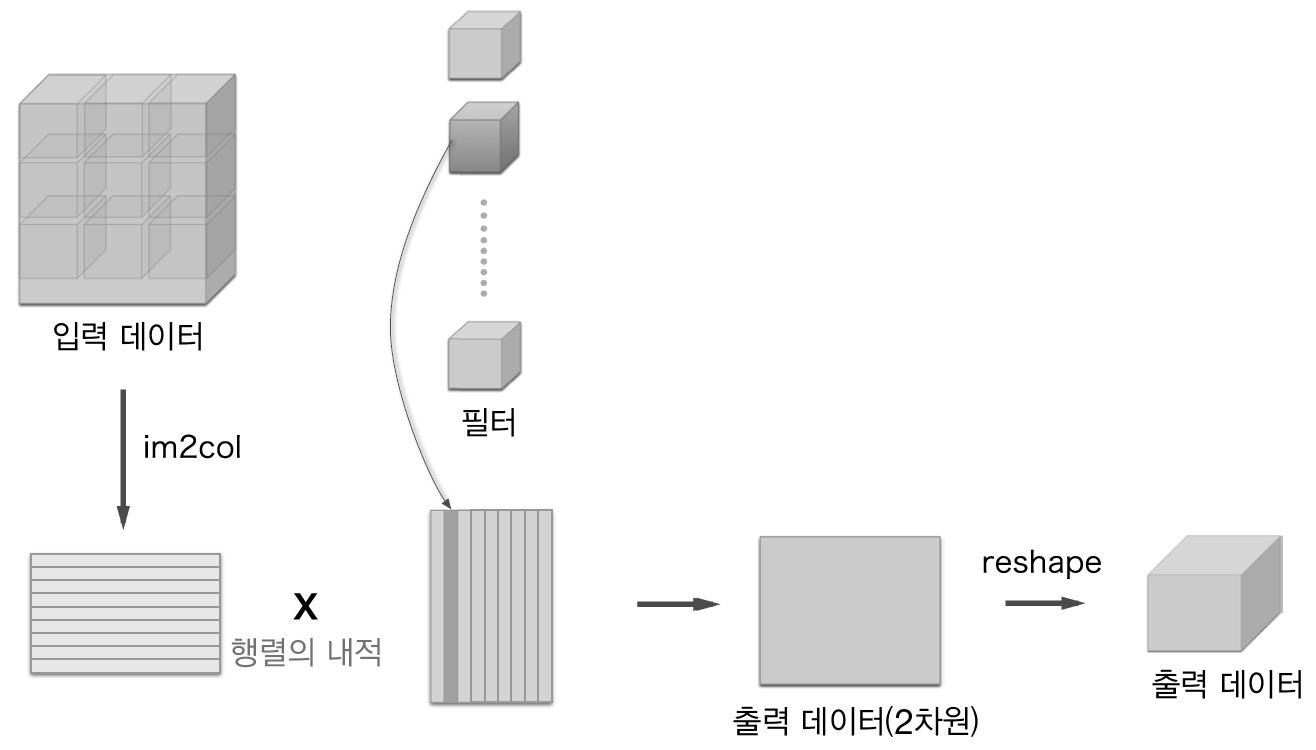
문제174. 위의 2개의 2차원을 내적하시오.
conv = np.dot(result, filter2.T) #result = 원본 2차원 이미지, filter2 = 필터 2차원 이미지
conv.shape #(900, 10)
합성곱층에서 일어나는 일은 이미지의 특징을 잡아낸 여러개의 피처맵을 생성하는 것인데 합성곱을 할 때 4차원의 이미지를 합성곱하면 시간이 너무 오래 걸리므로 2차원으로 변경해서 계산하는게 훨씬 속도가 빠름
1. 원본이미지 ---> im2col ---> 2차원으로 변경
2. 필터 ---> reshape ---> 2차원으로 변경
3. 2개의 2차원 이미지를 서로 내적하고(2차원 원본이미지 ◎ 2차원 필터.T)
4. 3번의 결과를 다시 4차원으로 변경
위의 작업이 아래 텐서플로우 한 줄에 녹아져 있음.
model.add(Conv2D(100,(3,3), padding = 'same', input_shape = (4,4,3)))
합성곱 계층 클래스로 구현
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W #필터행렬, 학습되면서 이 필터행렬이 원본이미지의 특징을 잘 살릴 수 있도록 변경됨
self.b = b
self.stride = stride
self.pad = pad
def forward(self, x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = int(1 + (H + 2*self.pad - FH) / self.stride)
out_w = int(1 + (W + 2*self.pad - FW) / self.stride)
col = im2col(x, FH, FW, self.stride, self.pad)
col_w = self.W.reshape(FN, -1).T
out = np.dot(col, col_w) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
return out
문제176. 점심시간 문제로 돌렸던 합성곱층 넣은 필기체 분류 3층 신경망의 배치정규화층을 추가해서 정확도를 더 올리시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense,Conv2D,MaxPooling2D, Flatten,BatchNormalization # 완전 연결계층, 합성곱층, pooling층, Flatten, 배치
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
import numpy as np
tf.random.set_seed(777)
(x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # mnist 데이터 로드
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
# print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)
# 2. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(28,28,1), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
model.add(Flatten()) # 완전연결계층에 들어갈 수 있도록 이미지(피처맵)를 1차원으로 변경해야함
model.add(Dense(50, activation = 'sigmoid', input_shape = (784, ))) # 1층
model.add(BatchNormalization())
model.add(Dense(50, activation = 'sigmoid') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='SGD',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
# 6. 모델을 훈련시킵니다.
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7. 모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
train_acc_list
test_acc_list=history.history['val_acc']
test_acc_list
# 8. 시각화
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()