딥러닝 / CNN구현
8 CNN구현하기 - p.250
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense,Conv2D,MaxPooling2D, Flatten,BatchNormalization # 완전 연결계층, 합성곱층, pooling층, Flatten, 배치
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
import numpy as np
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
(x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # mnist 데이터 로드
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
# print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)
# 2. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(28,28,1), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
model.add(Flatten()) # 완전연결계층에 들어갈 수 있도록 이미지(피처맵)를 1차원으로 변경해야함
model.add(Dense(50, activation = 'sigmoid', input_shape = (784, ))) # 1층
model.add(BatchNormalization())
model.add(Dense(50, activation = 'sigmoid') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='SGD',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
# 6. 모델을 훈련시킵니다.
# callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose = 1)]
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7. 모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
train_acc_list
test_acc_list=history.history['val_acc']
test_acc_list
# 8. 시각화
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()600/600 [==============================] - 7s 11ms/step - loss: 0.0042 - acc: 0.9999 - val_loss: 0.0333 - val_acc: 0.9897
313/313 [==============================] - 2s 5ms/step - loss: 0.0333 - acc: 0.9897
훈련데이터와 테스트데이터의 정확도가 99%를 보이고 있고 오버피팅도 발생하지 않고 있음.
지난번 fashion_mnist 데이터로 완전 연결계층을 구성했을 때 정확도가 겨우 90%를 넘겼음.
이제 cnn을 사용해보겠음.
문제189. 위의 배치정규화까지 추가한 코드에 입력 데이터를 mnist가 fashion_mnist로 변경하시오.
필기체 mnist는 훈련데이터 (60000,1,28,28), 테스트데이터 (10000,1,28,28)
fashion mnist는 훈련데이터 (50000,1,28,28), 테스트데이터 (10000,1,28,28)
fashion_mnist 불러오는 코드:
from tensorflow.keras.datasets.fashion_mnist import load_data
(x_train, y_train), (x_test, y_test) = load_data() # fashion_mnist 데이터# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
# from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.datasets.fashion_mnist import load_data #패션mnist
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense,Conv2D,MaxPooling2D, Flatten,BatchNormalization # 완전 연결계층, 합성곱층, pooling층, Flatten, 배치
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
import numpy as np
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
# (x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # 필기체 mnist 데이터 로드
(x_train, y_train), (x_test, y_test) = load_data() # fashion_mnist 데이터
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
# print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)
# 2. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(28,28,1), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
model.add(Flatten()) # 완전연결계층에 들어갈 수 있도록 이미지(피처맵)를 1차원으로 변경해야함
model.add(Dense(50, activation = 'sigmoid', input_shape = (784, ))) # 1층
model.add(BatchNormalization())
model.add(Dense(50, activation = 'sigmoid') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='SGD',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
# 6. 모델을 훈련시킵니다.
# callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose = 1)]
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7. 모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
train_acc_list
test_acc_list=history.history['val_acc']
test_acc_list
# 8. 시각화
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
600/600 [==============================] - 7s 11ms/step - loss: 0.0640 - acc: 0.9784 - val_loss: 0.3211 - val_acc: 0.9087
313/313 [==============================] - 2s 6ms/step - loss: 0.3211 - acc: 0.9087
정확도는 높게 나오는 편이지만 오버피팅 발생.
문제190. 드롭아웃 층을 넣어서 오버피팅을 줄이시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
# from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.datasets.fashion_mnist import load_data
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, BatchNormalization, Dropout # 완전 연결계층, 합성곱층, pooling층, Flatten, 배치
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
import numpy as np
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
# (x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # 필기체 mnist 데이터 로드
(x_train, y_train), (x_test, y_test) = load_data() # fashion_mnist 데이터
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
# print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)
# 2. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(28,28,1), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
model.add(Flatten()) # 완전연결계층에 들어갈 수 있도록 이미지(피처맵)를 1차원으로 변경해야함
model.add(Dense(50, activation = 'sigmoid', input_shape = (784, ))) # 1층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(50, activation = 'sigmoid') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='SGD',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
# 6. 모델을 훈련시킵니다.
# callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose = 1)]
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7. 모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
train_acc_list
test_acc_list=history.history['val_acc']
test_acc_list
# 8. 시각화
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
600/600 [==============================] - 7s 12ms/step - loss: 0.1088 - acc: 0.9621 - val_loss: 0.2956 - val_acc: 0.9097
313/313 [==============================] - 2s 5ms/step - loss: 0.2956 - acc: 0.9097
여전히 오버피팅 발생
문제191. 위의 경사하강법을 Adam으로 변경하고 활성화 함수를 relu로 변경하시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
# from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.datasets.fashion_mnist import load_data
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, BatchNormalization, Dropout # 완전 연결계층, 합성곱층, pooling층, Flatten, 배치
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
import numpy as np
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
# (x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # 필기체 mnist 데이터 로드
(x_train, y_train), (x_test, y_test) = load_data() # fashion_mnist 데이터
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
# print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)
# 2. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(28,28,1), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
model.add(Flatten()) # 완전연결계층에 들어갈 수 있도록 이미지(피처맵)를 1차원으로 변경해야함
model.add(Dense(50, activation = 'relu', input_shape = (784, ))) # 1층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(50, activation = 'relu') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='Adam',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
# 6. 모델을 훈련시킵니다.
# callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose = 1)]
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7. 모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
train_acc_list
test_acc_list=history.history['val_acc']
test_acc_list
# 8. 시각화
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()600/600 [==============================] - 7s 12ms/step - loss: 0.0528 - acc: 0.9806 - val_loss: 0.4164 - val_acc: 0.9111
313/313 [==============================] - 2s 5ms/step - loss: 0.4164 - acc: 0.9111

여전히 오버피팅
훈련 데이터의 정확도는 96에서 98로 올라갔고 테스트도 90에서 91로 올라갔음. 하지만 아직도 오버피팅이 발생함.
문제192. 드롭아웃 비율을 0.2에서 0.3으로 올리고 실험하시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
# from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.datasets.fashion_mnist import load_data
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, BatchNormalization, Dropout # 완전 연결계층, 합성곱층, pooling층, Flatten, 배치
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
import numpy as np
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
# (x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # 필기체 mnist 데이터 로드
(x_train, y_train), (x_test, y_test) = load_data() # fashion_mnist 데이터
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
# print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)
# 2. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(28,28,1), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
model.add(Flatten()) # 완전연결계층에 들어갈 수 있도록 이미지(피처맵)를 1차원으로 변경해야함
model.add(Dense(50, activation = 'relu', input_shape = (784, ))) # 1층
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(50, activation = 'relu') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='Adam',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
# 6. 모델을 훈련시킵니다.
# callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose = 1)]
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7. 모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
test_acc_list=history.history['val_acc']
# 8. 시각화
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()
문제193. 배치정규화와 드롭아웃을 CNN층에도 추가시키시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
# from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.datasets.fashion_mnist import load_data
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, BatchNormalization, Dropout # 완전 연결계층, 합성곱층, pooling층, Flatten, 배치
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
import numpy as np
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
# (x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # 필기체 mnist 데이터 로드
(x_train, y_train), (x_test, y_test) = load_data() # fashion_mnist 데이터
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
# print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)
# 2. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(28,28,1), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
model.add(Dropout(0.3))
model.add(Flatten()) # 완전연결계층에 들어갈 수 있도록 이미지(피처맵)를 1차원으로 변경해야함
model.add(Dense(50, activation = 'relu', input_shape = (784, ))) # 1층
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(50, activation = 'relu') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='Adam',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
# 6. 모델을 훈련시킵니다.
# callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose = 1)]
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7. 모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
test_acc_list=history.history['val_acc']
# 8. 시각화
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()600/600 [==============================] - 9s 15ms/step - loss: 0.1058 - acc: 0.9616 - val_loss: 0.2840 - val_acc: 0.9189
313/313 [==============================] - 2s 5ms/step - loss: 0.2840 - acc: 0.9189
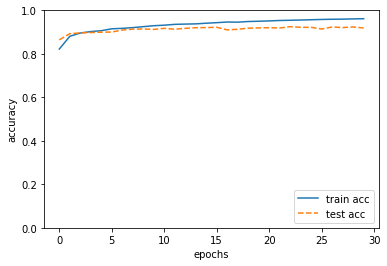
문제194. 합성곱층을 하나 더 추가해서 돌리시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
# from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.datasets.fashion_mnist import load_data
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, BatchNormalization, Dropout # 완전 연결계층, 합성곱층, pooling층, Flatten, 배치
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
import numpy as np
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
# (x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # 필기체 mnist 데이터 로드
(x_train, y_train), (x_test, y_test) = load_data() # fashion_mnist 데이터
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
# print(x_train.shape, x_test.shape) #(60000, 28, 28, 1) (10000, 28, 28, 1)
# 2. 정규화 진행
x_train = x_train / 255
x_test = x_test / 255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델을 구성합니다. 3층 신경망으로 구성
model = Sequential()
model.add(Conv2D(100, kernel_size=(5,5), input_shape=(28,28,1), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(BatchNormalization())
# model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
# model.add(Dropout(0.3))
model.add(Conv2D(100, kernel_size=(5,5), padding='same', activation='relu') ) # 흑백색조(,,1)
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size = (2,2), padding = 'same')) #이미지를 선명하게 해주는 층
model.add(Dropout(0.3))
model.add(Flatten()) # 완전연결계층에 들어갈 수 있도록 이미지(피처맵)를 1차원으로 변경해야함
model.add(Dense(50, activation = 'relu', input_shape = (784, ))) # 1층
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(50, activation = 'relu') ) # 2층 은닉층
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Dense(10, activation = 'softmax')) # 3층 출력층
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer='Adam',
loss = 'categorical_crossentropy',
metrics=['acc']) # 학습과정에서 정확도를 보려고
# 6. 모델을 훈련시킵니다.
history = model.fit(x_train, y_train,
epochs = 30, # 30에폭
batch_size = 100,
validation_data=(x_test, y_test) )
# 7. 모델을 평가합니다. (오차, 정확도가 출력됩니다.)
model.evaluate(x_test, y_test)
train_acc_list=history.history['acc']
test_acc_list=history.history['val_acc']
# 8. 시각화
import matplotlib.pyplot as plt
x = np.arange( len(train_acc_list) )
plt.plot( x, train_acc_list, label='train acc')
plt.plot( x, test_acc_list, label='test acc', linestyle='--')
plt.ylim(0, 1)
plt.legend(loc='lower right')
plt.xlabel('epochs')
plt.ylabel('accuracy')
plt.show()Epoch 30/30
600/600 [==============================] - 22s 36ms/step - loss: 0.0473 - acc: 0.9835 - val_loss: 0.2916 - val_acc: 0.9315
313/313 [==============================] - 3s 8ms/step - loss: 0.2916 - acc: 0.9315
