4장의 학습내용 : 신경망을 학습 시키기 위해서 알아야 하는 내용 3가지
1. 오차함수 : 신경망이 뭘 잘못하고 있는지 깨닫게 해주는 함수
오차함수에 정답 데이터와 예측 데이터를 넣어서 오차가 어떻게 되는지 확인합니다.
2. 미니배치 : 학습할 때 데이터를 한꺼번에 신경망에 넣는게 아니라 몇백장씩 조금씩 신경망에 넣고 학습시키는 것
3. 수치미분 : 모델의 기울기를 구해서 기울기만큼 가중치를 갱신할 때 필요
1 크로스 엔트로피 오차함수 - p.111
오차함수는 신경망이 뭘 잘못하고 있는지 깨닫게 해주는 함수
1. 평균 제곱 오차함수(mean squared error) : 회귀분석할 때 사용
2. 교차 엔트로피 오차함수(cross entropy error) : 분류할 때 사용


문제52. 위의 그림처럼 단층 신경망의 행렬을 내적해서 k행렬을 출력하시오.
import numpy as np
x = np.array([0.6,0.9]).reshape(1,2)
w = np.array([0.4,0.7,0.9,0.2,0.3,0.1]).reshape(2,3)
k = np.dot(x,w)
k #array([[0.42, 0.69, 0.63]])
문제53. 위의 k행렬값을 softmax 함수에 넣고 결과를 출력하시오.
import numpy as np
x = np.array([0.6,0.9]).reshape(1,2)
w = np.array([0.4,0.7,0.9,0.2,0.3,0.1]).reshape(2,3)
k = np.dot(x,w)
k #array([[0.42, 0.69, 0.63]])
def softmax(a):
C = np.max(a)
minus = a - C
exp_a = np.exp(minus)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
y = softmax(k)
print(y) #[[0.28219551 0.36966608 0.34813841]]실제 정답은 [0,0,1]인데 지금 [0,1,0]으로 예측하고 있으므로 오차가 발생했음. 이 오차가 얼마인지 구해서 다시 신경망에 역전파 시켜줘야함.
문제54. 책 115이제 맨 위에 나오는 교차 엔트로피 함수를 생성하시오.
def cross_entropy_error(y,t): # y는 예측값, t는 label
delta = 1e - 7 # 0은 아닌데 0에 가까운 아주 작은 수(컴퓨터로 계산하기 위함임)
return -np.sum(t * np.log(y + delta))아주 작은 수(delta)를 더한 이유?
y가 0이 되면 마이너스 무한대가 되기 때문에 마이너스 무한대값이 출력되지 않도록 아주 작은 값을 더함.
문제55. 위에서 출력한 y행렬값과 정답 [0,0,1]을 오차함수에 넣고 오차를 출력하시오.
def cross_entropy_error(y,t):
delta = 1e-7 # 0은 아닌데 0에 가까운 아주 작은 수(컴퓨터로 계산하기 위함임)
return -np.sum(t * np.log(y + delta))
t = np.array([0,0,1]).reshape(1,3)
cross_entropy_error(y,t) #1.0551548687114343
문제56. 위의 오차함수 그림 단층 신경망을 텐서 플로우로 구현하시오.
입력값은 그림대로 제공하고 가중치는 텐서 플로우가 알아서 하게 하시오.
#1. 필요한 패키지 로드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
#2. 데이터 생성
x = np.array([0.6,0.9]).reshape(1,2) # 입력데이터
y = np.array([0,0,1]).reshape(1,3) # label 데이터
#3. 모델 구성
model = Sequential()
model.add(Dense(3, input_shape = (2,), activation = 'softmax'))
#4. 모델 준비하기
model.compile( optimizer= "adam", # 경사하강법
loss= 'categorical_crossentropy', #오차함수
metrics = ['acc'] ) # list 형태로 평가지표를 전달
#5. 학습시키기
model.fit(x,y,epochs = 30)이진분류 : binary_crossentropy, 다중분류 : categorical_crossentropy
ㅇ신경망으로 풀고자 하는 문제
1. 분류 ---> 오차함수 : 교차엔트로피 함수 사용
2. 회귀 ---> 오차함수 : 평균 제곱 함수 사용
문제57. 아래 그림의 신경망을 텐서 플로우로 구현하시오.
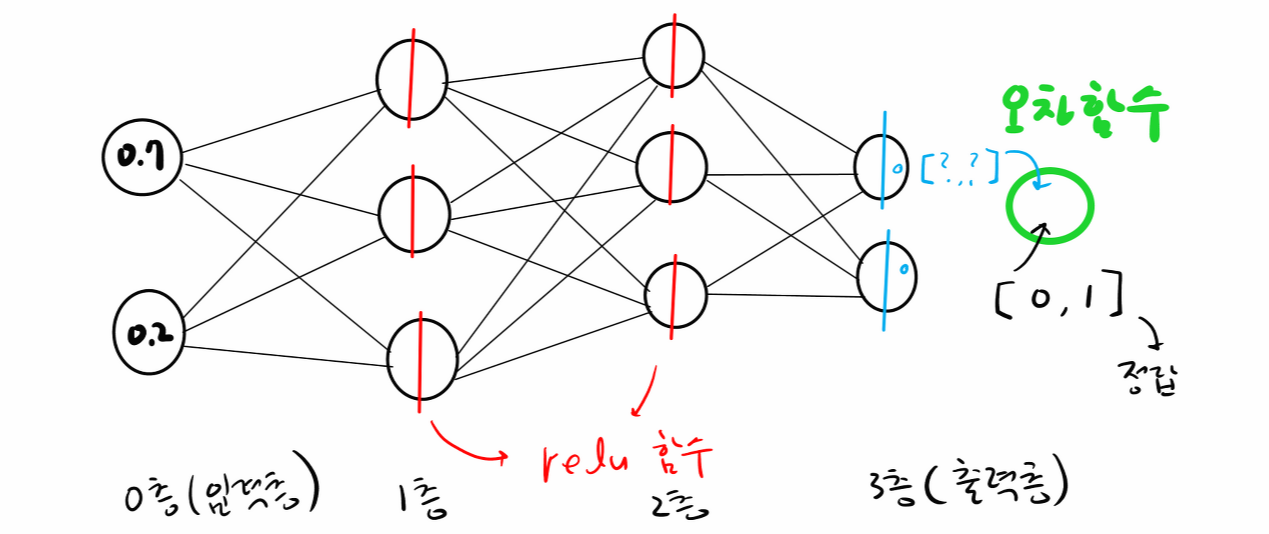
#1. 필요한 패키지 로드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import tensorflow as tf
tf.random.set_seed(777) # 시드 설정
#2. 데이터 생성
x = np.array([0.7, 0.2]).reshape(1,2) # 입력데이터
y = np.array([0,1]).reshape(1,2) # label 데이터
#3. 모델 구성
model = Sequential()
model.add(Dense(3, input_shape = (2,), activation = 'relu'))
model.add(Dense(3, activation = 'relu'))
model.add(Dense(2, activation = 'softmax')) #출력층
#4. 모델 준비하기
model.compile( optimizer= "adam", # 경사하강법
loss= 'categorical_crossentropy', #오차함수
metrics = ['acc'] ) # list 형태로 평가지표를 전달
#5. 학습시키기 - 분류
model.fit(x,y,epochs = 30)
#6. 오차함수, 정확도 확인
model.evaluate(x,y) #[0.6636707186698914, 1.0]
2 평균제곱 오차함수 - p.112
신경망으로 풀고자하는 문제가 수치예측이면 평균제곱 오차함수를 사용하면 됩니다.
ex. 콘크리트 강도 예측, 보스톤 지역 집값 예측
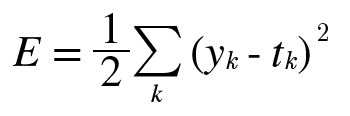
def mean_squared_error(y,t): # y는 예측값, t는 label
return 0.5 * np.sum( (y-t)**2 )
문제59. 위에서 만든 평균제곱 오차함수를 이용하기 위해 아래의 정답과 예측값을 만들고 평균제곱 오차함수에 입력하시오.
# 데이터
y = np.array([0.1, 0.05, 0.6, 0.0, 0.05, 0.1, 0.0, 0.0, 0.0, 0.0]) # 예측값
t = np.array([0,0,1,0,0,0,0,0,0,0]) #정답값
#오차함수
def mean_squared_error(y,t):
return 0.5 * np.sum( (y-t)**2 )
#결과
mean_squared_error(y,t) #0.09250000000000003
문제60. 숫자7로 예측한 결과와 정답 숫자 2와의 오차를 구하시오.
# 데이터
y = np.array([0.1, 0.05, 0.0, 0.0, 0.05, 0.1, 0.0, 0.6, 0.0, 0.0]) # 예측값
t = np.array([0,0,1,0,0,0,0,0,0,0]) #정답값
#오차함수
def mean_squared_error(y,t):
return 0.5 * np.sum( (y-t)**2 )
#결과
mean_squared_error(y,t) #0.6925이번에는 잘못 예측했으므로 오차가 크게 출력되고 있음.
정리하면 텐서플로우에서 위의 오차함수를 사용하는 코드
model.compile( optimizer= "adam", # 경사하강법
loss= 'categorical_crossentropy', #오차함수
metrics = ['acc'] ) # list 형태로 평가지표를 전달
-> 분류 : categorical_crossentropy / 수치예측 : mse 적용하면 됨
ㅇ수치 예측하는 텐서플로우 신경망 전체 코드(보스톤 지역의 집값 예측)
#1. 데이터 로드
from tensorflow.keras.datasets.boston_housing import load_data
(x_train, y_train), (x_test, y_test) = load_data(path='boston_housing.npz',
test_split=0.2, seed=777 )
print(x_train.shape) # (404, 13)
print(y_train.shape) # (404. 3 )
print(x_test.shape) # (102, 13)
print(y_test.shape) # (102,)
#2. 모델 생성하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import tensorflow as tf
tf.random.set_seed(777) # 시드 설정
model = Sequential()
model.add( Dense( 64, activation='relu', input_shape=(13, ) ) )
model.add( Dense( 32, activation='relu') )
model.add( Dense(1) ) # 출력층에는 분류가 아니라 softmax 함수가 필요없습니다.
# 예측되는 집값이 그대로 출력되면 됩니다.
#3. 모델 설정하기
model.compile(optimizer='adam', loss='mse', metrics=['mae'] ) # mae : 오차
#4. 모델 훈련하기
model.fit( x_train, y_train, epochs=100, verbose = 0 )
#5. 모델 평가하기
model.evaluate( x_test, y_test) #[31.305849075317383, 4.3813157081604][31.305849075317383, 4.3813157081604]
mse mae (평균 절대 오차)
문제61. 위의 오차값이 아니라 예측값과 실제값과의 상관계수로 모델을 평가하시오.
result = model.predict(x_test)
np.corrcoef(result.flatten(), y_test) #0.79577571
문제62. 위의 신경망의 성능을 더 올리기 위해 입력 데이터를 표준화하고 실험해봅니다.
아래의 표준화 코드를 전체 코드에 추가하여 상관관계를 확인합니다.
mean = np.mean(x_train, axis = 0)
std = np.std(x_train, axis = 0)
x_train = (x_train - mean) / std
x_test = (x_test - mean) / std전체코드 :
#1. 데이터 로드
from tensorflow.keras.datasets.boston_housing import load_data
(x_train, y_train), (x_test, y_test) = load_data(path='boston_housing.npz',
test_split=0.2, seed=777 )
print(x_train.shape) # (404, 13)
print(y_train.shape) # (404. 3 )
print(x_test.shape) # (102, 13)
print(y_test.shape) # (102,)
x_train = (x_train - np.min(x_train, axis = 0)) / (np.max(x_train, axis = 0) - np.min(x_train, axis = 0))
x_test = (x_test - np.min(x_test, axis = 0)) / (np.max(x_test, axis = 0) - np.min(x_test, axis = 0))
#2. 모델 생성하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import tensorflow as tf
tf.random.set_seed(777) # 시드 설정
model = Sequential()
model.add( Dense( 64, activation='relu', input_shape=(13, ) ) )
model.add( Dense( 32, activation='relu') )
model.add( Dense(1) ) # 출력층에는 분류가 아니라 softmax 함수가 필요없습니다.
# 예측되는 집값이 그대로 출력되면 됩니다.
#3. 모델 설정하기
model.compile(optimizer='adam', loss='mse', metrics=['mae'] ) # mae : 오차
#4. 모델 훈련하기
model.fit( x_train, y_train, epochs=100, verbose = 0 )
#5. 모델 평가하기
model.evaluate( x_test, y_test) #[15.22754955291748, 2.8739681243896484]
result = model.predict(x_test)
np.corrcoef(result.flatten(), y_test) #0.90346945상관계수가 0.79577571 --->0.94350984 로 증가함.
분류를 할 때는 minmax정규화가 더 성능이 잘 나오고 수치예측할 때는 표준화가 더 성능이 잘 나옴.
문제63. 이번에는 정규화 하기전의 오차와 정규화 한 후의 오차를 비교하시오.
정규화 코드 :
max_x = np.max(x_train,axis = 0)
min_x = np.min(x_train,axis = 0)
x_train = (x_train - min_x) / (max_x - min_x)
x_test = (x_test - min_x) / (max_x - min_x)전체코드:
#1. 데이터 로드
from tensorflow.keras.datasets.boston_housing import load_data
(x_train, y_train), (x_test, y_test) = load_data(path='boston_housing.npz',
test_split=0.2, seed=777 )
print(x_train.shape) # (404, 13)
print(y_train.shape) # (404. 3 )
print(x_test.shape) # (102, 13)
print(y_test.shape) # (102,)
# 정규화(수정. x_train데이터의 max/min값을 x_test에도 적용시킴)
max_x = np.max(x_train,axis = 0)
min_x = np.min(x_train,axis = 0)
x_train = (x_train - min_x) / (max_x - min_x)
x_test = (x_test - min_x) / (max_x - min_x)
#2. 모델 생성하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import tensorflow as tf
tf.random.set_seed(777) # 시드 설정
model = Sequential()
model.add( Dense( 64, activation='relu', input_shape=(13, ) ) )
model.add( Dense( 32, activation='relu') )
model.add( Dense(1) ) # 출력층에는 분류가 아니라 softmax 함수가 필요없습니다.
# 예측되는 집값이 그대로 출력되면 됩니다.
#3. 모델 설정하기
model.compile(optimizer='adam', loss='mse', metrics=['mae'] ) # mae : 오차
#4. 모델 훈련하기
model.fit( x_train, y_train, epochs=100, verbose = 0 )
#5. 모델 평가하기
model.evaluate( x_test, y_test) #[14.272588729858398, 2.6685783863067627]
result = model.predict(x_test)
np.corrcoef(result.flatten(), y_test) #0.90975714
'Study > class note' 카테고리의 다른 글
| 딥러닝 / 텐서플로우로 신경망 구현하기 (0) | 2022.04.07 |
|---|---|
| 딥러닝 / 미니배치, 수치미분, 편미분, 신경망에서 기울기 (0) | 2022.04.06 |
| 딥러닝 / 배치처리 (0) | 2022.04.05 |
| 딥러닝 / 손글씨 필기체 인식하는 신경망 만들기 (0) | 2022.04.04 |
| 딥러닝 / 다차원 배열, 3층신경망 구현, 소프트맥스 함수 (0) | 2022.04.01 |



