ㅇ오버피팅 문제를 해결하는 방법 2가지
1. 드롭아웃
2. L2정규화
4 드롭아웃 - p219
오버피팅을 억제하기 위해서 뉴런을 임의로 삭제하면서 학습 시키는 방법
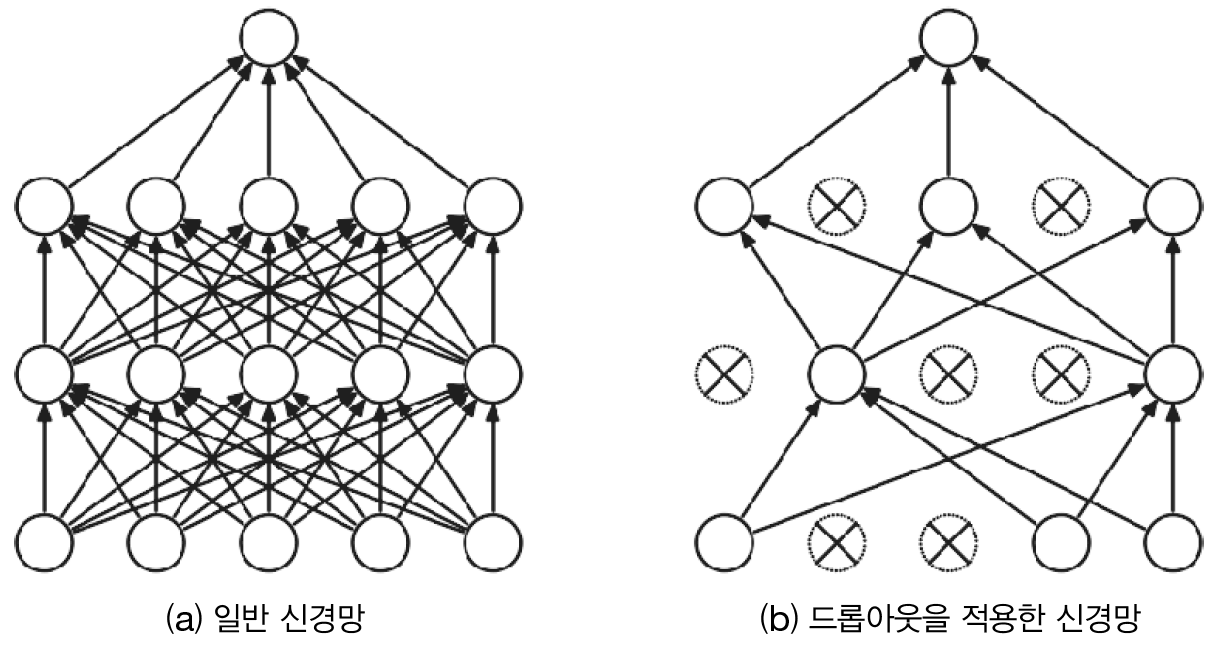
사공이 많으면 배가 산으로 간다는 속담 연상.
뉴런을 삭제하게 되면 훈련 데이터의 정확도와 테스트 데이터의 정확도가 비슷해지는 현상이 나타남.
그런데 뉴런을 너무 많이 삭제하면 훈련 데이터, 테스트 데이터 둘 다 정확도가 떨어질 수 잇음.
ㅇ드롭아웃을 구성할 때 적용하는 방법
model = Sequential()
model.add(Flatten(input_shape = (28,28)))
model.add(Dense(50, activation = opt[i][1])) #은닉층(1층)
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(50, activation = opt[i][1])) #은닉층(2층)
model.add(BatchNormalization())
model.add(Dropout(0.2))
model.add(Dense(10, activation = 'softmax')) #출력층
러닝레이트 없이 Adam_relu로 구성한 3층 신경망의 정확도
훈련데이터 정확도 : 0.9729333519935608, 테스트데이터 정확도 : 0.973800003528595
문제140. 드롯아웃 비율을 0.1로 했을 때, 즉 뉴런의 갯수를 랜덤으로 신경망에서 10%만 삭제했을 때의 결과는 어떻게 나오는지 실험하시오.
훈련데이터 정확도 : 0.9835333228111267, 테스트데이터 정확도 : 0.9746999740600586

-> 훈련데이터와 테스트 데이터의 정확도가 비슷해지거나 테스트데이터의 정확도가 훈련 데이터의 정확도를 역전하는 그 시점에서 학습을 멈추겠다 -> early stop

ㅇ early stop 코드
from tensorflow.keras.callbacks import EarlyStopping
#콜백 정의
callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose =1)]
model.fit(x_train, y_train,
batch_size = 100,
validation_data = (x_test, y_test),
epochs = 30,
callbacks = callbacks)monitor : 관찰하고자 하는 항목으로 'val_loss'또는 'val_acc'를 주로 사용함
patience : 학습을 하다가 개선이 없다고 바로 종료하지 않고 위의 그림처럼 4번은 참아주고 종료
verbose : 얼마나 자세하게 정보를 표현할 것인가 지정
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense # 완전 연결계층을 구성하기 위한 모듈
from tensorflow.keras.layers import Flatten, BatchNormalization, Dropout
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
from tensorflow.keras import backend as K
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
(x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # mnist 데이터 로드
# 2. 정규화 진행
x_train = x_train.reshape(60000, 28*28)/255
x_test = x_test.reshape(10000, 28*28)/255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델 구성 + 배치정규화
model = Sequential()
model.add(Dense(50, activation='relu', input_shape=(784, ))) # 은닉층(1층)
model.add(BatchNormalization())
model.add(Dropout(0.1))
model.add(Dense(50, activation='relu') ) # 은닉층(2층)
model.add(BatchNormalization())
model.add(Dropout(0.1))
model.add(Dense(10, activation='softmax') ) #출력층(3층)
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer= 'Adam',
loss = 'categorical_crossentropy',
metrics=['acc'])
#6. 모델을 훈련시킵니다.
#러닝레이트
# K.set_value(model.optimizer.learning_rate, 0.1)
#콜백정의
callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose =1)]
history = model.fit(x_train, y_train,
batch_size = 100,
validation_data = (x_test, y_test),
epochs = 30,
callbacks = callbacks)
model.evaluate(x_test, y_test, verbose = 0)
train_acc_list = history.history['acc']
test_acc_list = history.history['val_acc']
# 7.모델을 평가합니다. (오차, 정확도가 출력됩니다.)
print(f'훈련데이터 정확도 : {train_acc_list[-1]}, 테스트데이터 정확도 : {test_acc_list[-1]} ')Epoch 15: early stopping
훈련데이터 정확도 : 0.9765999913215637, 테스트데이터 정확도 : 0.9742000102996826
문제141. 위에서 학습조기종료된 상태의 모델을 mnist_model.h5로 저장하시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense # 완전 연결계층을 구성하기 위한 모듈
from tensorflow.keras.layers import Flatten, BatchNormalization, Dropout
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
from tensorflow.keras import backend as K
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
(x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # mnist 데이터 로드
# 2. 정규화 진행
x_train = x_train.reshape(60000, 28*28)/255
x_test = x_test.reshape(10000, 28*28)/255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델 구성 + 배치정규화
model = Sequential()
model.add(Dense(50, activation='relu', input_shape=(784, ))) # 은닉층(1층)
model.add(BatchNormalization())
model.add(Dropout(0.1))
model.add(Dense(50, activation='relu') ) # 은닉층(2층)
model.add(BatchNormalization())
model.add(Dropout(0.1))
model.add(Dense(10, activation='softmax') ) #출력층(3층)
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer= 'Adam',
loss = 'categorical_crossentropy',
metrics=['acc'])
#6. 모델을 훈련시킵니다.
#러닝레이트
#K.set_value(model.optimizer.learning_rate, 0.1)
#콜백정의
callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose =1)]
history = model.fit(x_train, y_train,
batch_size = 100,
validation_data = (x_test, y_test),
epochs = 30,
callbacks = callbacks, verbose = 0)
model.evaluate(x_test, y_test, verbose = 0)
train_acc_list = history.history['acc']
test_acc_list = history.history['val_acc']
# 7.모델을 평가합니다. (오차, 정확도가 출력됩니다.)
print(history.params)
print(f'훈련데이터 정확도 : {train_acc_list[-1]}, 테스트데이터 정확도 : {test_acc_list[-1]} ')
#8. 모델 저장
model.save("c:\\deep\\mnist_model.h5")
6 가중치 감소 - p217
학습하는 과정에서 큰 가중치에 대해서는 그에 상응하는 큰 패널티를 부여하여 오버피팅을 억제하는 방법
고양이와 개를 분류하는 신경망이 고양이 사진 수천장을 계속해서 학습하다보니 고양이는 귀가 뾰족하다는게 고양이와 개를 분류하는데 있어서 아주 중요하다는 것을 알게 되었음.
아주 큰 가중치에 대해서는 큰 패널티를 부여해서 가중치의 매개변수값이 작아지도록 만드는 학습방법이 가중치 감소입니다. 작은 가중치에 대해서는 작은 패널티를 부여하고 큰 가중치에 대해서는 큰 패널티를 부여하게 해서 오버피팅을 막는 것입니다.
아주 큰 가중치에 대해서는 큰 패널티를 부여해서 가중치의 매개변수값이 작아지도록 만드는 학습방법이 가중치 감소입니다.
ㅇ텐서플로우 구현방법
model.add(Dense(50, kernel_regularizer = 'l2', activation = 'relu'))
문제142. 지금까지 텐서플로우로 만든 3층 신경망에 dropout은 걷어내고 대신 l2정규화 코드를 추가해서 오버피팅 여부를 확인하시오.
# 1. 필요한 패키지 가져오는 코드
import tensorflow as tf # 텐써 플로우 2.0
from tensorflow.keras.datasets.mnist import load_data # 텐써플로우에 내장되어있는
# mnist 데이터를 가져온다.
from tensorflow.keras.models import Sequential # 모델을 구성하기 위한 모듈
from tensorflow.keras.layers import Dense # 완전 연결계층을 구성하기 위한 모듈
from tensorflow.keras.layers import Flatten, BatchNormalization, Dropout
from tensorflow.keras.utils import to_categorical # one encoding 하는 모듈
from tensorflow.keras import backend as K
from tensorflow.keras.callbacks import EarlyStopping
tf.random.set_seed(777)
(x_train, y_train), (x_test, y_test) = load_data(path='mnist.npz') # mnist 데이터 로드
# 2. 정규화 진행
x_train = x_train.reshape(60000, 28*28)/255
x_test = x_test.reshape(10000, 28*28)/255
# 3. 정답 데이터를 준비한다.
# 하나의 숫자를 one hot encoding 한다. (예: 4 ---> 0 0 0 0 1 0 0 0 0 0 )
y_train = to_categorical(y_train) # 훈련 데이터의 라벨(정답)을 원핫 인코딩
y_test = to_categorical(y_test) # 테스트 데이터의 라벨(정답)을 원핫 인코딩
# 4. 모델 구성 + 배치정규화
model = Sequential()
model.add(Dense(50, kernel_regularizer = 'l2', activation='relu', input_shape=(784, ))) # 은닉층(1층)
model.add(BatchNormalization())
model.add(Dense(50, kernel_regularizer = 'l2', activation='relu') ) # 은닉층(2층)
model.add(BatchNormalization())
model.add(Dense(10, kernel_regularizer = 'l2', activation='softmax') ) #출력층(3층)
# 5. 모델을 설정합니다. ( 경사하강법, 오차함수를 정의해줍니다. )
model.compile(optimizer= 'Adam',
loss = 'categorical_crossentropy',
metrics=['acc'])
#6. 모델을 훈련시킵니다.
#러닝레이트
#K.set_value(model.optimizer.learning_rate, 0.1)
#콜백정의
# callbacks = [EarlyStopping(monitor = 'val_acc',patience = 4, verbose =1)]
history = model.fit(x_train, y_train,
batch_size = 100,
validation_data = (x_test, y_test),
epochs = 30,
callbacks = callbacks, verbose = 0)
model.evaluate(x_test, y_test, verbose = 0)
train_acc_list = history.history['acc']
test_acc_list = history.history['val_acc']
# 7.모델을 평가합니다. (오차, 정확도가 출력됩니다.)
print(history.params)
print(f'훈련데이터 정확도 : {train_acc_list[-1]}, 테스트데이터 정확도 : {test_acc_list[-1]} ')L2정규화 안 썼을 떄
훈련데이터 정확도 : 0.9954166412353516, 테스트데이터 정확도 : 0.9726999998092651 L2정규화 썼을 때
훈련데이터 정확도 : 0.966616690158844, 테스트데이터 정확도 : 0.9577000141143799
드롯아웃 0.2로 했더니 오버피팅은 안일어났는데 정확도가 너무 떨어졌고, 드롭아웃 0.1로 했더니 정확도는 다소 높아졌는데 오버피팅이 발생했다면 0.1~0.2 사이에서 적절한 드롭아웃 비율을 찾게끔 범위를 좁혀나가야함.
'Study > class note' 카테고리의 다른 글
| 딥러닝 / 3차원 데이터의 합성곱 연산 (0) | 2022.04.15 |
|---|---|
| 딥러닝 / 합성곱 신경망(Convolution Neural Network) (0) | 2022.04.14 |
| 딥러닝 / 언더피팅 방지(경사하강법과 활성화 함수의 조합을 적절하게 조합하기) (0) | 2022.04.14 |
| 딥러닝 / 언더피팅 방지(가중치 초기값, 배치정규화) (0) | 2022.04.13 |
| 딥러닝 / 2층 신경망을 텐서 플로우로 구현 (0) | 2022.04.13 |



