#1. R을 이용해서 스마트폰 만족도에 영향을 미치는 요소가 무엇인지 기울기와 절편 출력하기
# R
reg <- function(y,x){
x <- as.matrix(x) # x에 들어오는 값들을 행렬로 변환하는 코드
x <- cbind(intercept = 1,x) #intercept는 컬럼명을 붙여준 것임. 그냥 1만 써도 됨, 절편+독립변수 행렬
beta <- solve(t(x) %*% x) %*% t(x) %*% y # 기울기 구하는 수학식
colnames(beta) <- "estimate" #수치예측이라는 컬럼명 지정
print(beta)
}
smart <- read.csv("c:\\data\\multi_hg.csv", header = T)
head(smart)
x <- smart[,-4]
y <- smart[,4]
reg(y,x) estimate
intercept 3.5136006
외관 0.2694261
편의성 0.2105249
유용성 0.1623154
#2. 파이썬으로 위의 코드를 구현하기
#python
import pandas as pd
import numpy as np
smart = pd.read_csv("c:\\data\\multi_hg.csv", encoding = 'euckr')
def reg(y,x):
x_c = x.columns
x['intercept'] = 1
# x_c = x.columns
x = x.to_numpy()
B = np.dot(np.linalg.inv(np.dot(x.T,x)),np.dot(x.T,y))
for i in range(len(x_c)):
print(x_c[i],B[i])
reg(smart['만족감'],smart.iloc[:,:-1])문제313. R에서와 같이 파이썬에서도 아래와 같이 절편이 출력되도록 파이썬 reg 함수의 코드를 수정하시오.
#python
import pandas as pd
import numpy as np
smart = pd.read_csv("c:\\data\\multi_hg.csv", encoding = 'euckr')
def reg(y,x):
x_c = x.columns
x['intercept'] = 1
# x_c = x.columns
x = x.to_numpy()
B = np.dot(np.linalg.inv(np.dot(x.T,x)),np.dot(x.T,y))
print('intercept',B[3])
for i in range(len(x_c)):
print(x_c[i],B[i])
reg(smart['만족감'],smart.iloc[:,:-1])intercept 3.5136006173296646
외관 0.2694261422303653
편의성 0.21052493029347552
유용성 0.16231535532284308
58 다중공선성 실험하기(R 과 파이썬)
-다중회귀분석시에 독립변수들간의 다중 공선성 확인을 파이썬으로 실험하기
다중 회귀 분석을하고 결과를 봤더니 유의한 변수들을 발견할 수 없었다고 한다면 다중 공선성을 의심해봐야 합니다.
다중회귀분석을 했는데 결과에서 유의한 변수들이 보이지 않는다면 독립변수들끼리의 상관관계가 아주 높은지 의심해봐야 합니다.
만약 독립변수들끼리의 상관관계가 아주 강하여 절대값 1에 가까워지면 최소제곱법 적용자체가 매우 심각한 국면을 맞이하게 됩니다.
이때 나타나는 현상을 다중 공선성이라고 함.
ㅇR을 활용해서 다중공선성 테스트하기
#1. 다중 공선성 vif(팽창계수)를 확인할 수 있는 패키지를 설치
#2. 데이터 로드
#3. 독립변수들끼리의 상관관계를 확인
#4. 회귀모델을 생성
#5. 다중공선성 문제를 보이는지 확인
#1. 다중 공선성 vif(팽창계수)를 확인할 수 있는 패키지를 설치
library(car)
#2. 데이터 로드
test <- read.csv("c:\\data\\test_vif1.csv")
test종속변수 : 시험점수
독립변수 : 아이큐, 공부시간
귀무가설 : 시험점수는 아이큐와 관계가 없다, 시험점수는 공부시간과 관계가 없다.
대립가설 : 시험점수는 아이큐와 관계가 있다, 시험점수는 공부시간과 관계가 있다.
#3. 독립변수들끼리의 상관관계를 확인
cor( test[ , c("아이큐","공부시간")]) 아이큐 공부시간
아이큐 1.0000000 0.7710712
공부시간 0.7710712 1.0000000
> 두 독립변수들끼리의 상관관계가 강한 양의 상관관계를 보이고 있음.
#4. 회귀모델을 생성
model <- lm(시험점수 ~ 아이큐 + 공부시간, data = test)
summary(model)Residuals:
Min 1Q Median 3Q Max
-6.341 -1.130 -0.191 1.450 5.542
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 23.1561 15.9672 1.450 0.1903
아이큐 0.5094 0.1808 2.818 0.0259 *
공부시간 0.4671 0.1720 2.717 0.0299 *
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.875 on 7 degrees of freedom
Multiple R-squared: 0.9053, Adjusted R-squared: 0.8782
F-statistic: 33.45 on 2 and 7 DF, p-value: 0.0002617
결정계수도 0.90으로 1에 가까운 설명력을 보이고 있고 아이큐, 공부시간 둘 다 p-value가 0.02로 유의수준 0.05보다 작으므로 유의미한 변수임이 확인되고 있음. 따라서 대립가설을 채택할 충분한 근거가 이음.
#5. 다중공선성 문제를 보이는지 확인
library(car)
vif(model) > 10 아이큐 공부시간
FALSE FALSE
> 공부시간과 아이큐는 서로 상관관계는 높았으나(0.77) 팽창계수가 높지 않아 이 회귀모델은 적절한 모형임이 확인됨.
#6. test_vif2 로드
test2 <- read.csv("c:\\data\\test_vif2.csv")
test2종속변수 : 시험점수
독립변수 : 아이큐, 공부시간, 등급평균
귀무가설 : 아이큐는 시험점수와 관련이 없다. 공부시간은 시험점수와 관련이 없다. 등급평균은 시험점수와 관련이 없다.
대립가설 : 아이큐는 시험점수와 관련이 있다. 공부시간은 시험점수와 관련이 있다. 등급평균은 시험점수와 관련이 있다.
#7. 독립변수들끼리의 상관관계를 확인
cor(test2[ , c("아이큐","공부시간","등급평균")]) 아이큐 공부시간 등급평균
아이큐 1.0000000 0.7710712 0.9736894
공부시간 0.7710712 1.0000000 0.7300546
등급평균 0.9736894 0.7300546 1.0000000
> 아이큐와 등급평균의 상관관계가 굉장히 높음.
#8. 회귀모델 생성
model2 <- lm(시험점수 ~ 아이큐+공부시간+등급평균, data = test2)
summary(model2)Residuals:
Min 1Q Median 3Q Max
-6.3146 -1.2184 -0.4266 1.5516 5.6358
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 50.30669 35.70317 1.409 0.2085
아이큐 0.05875 0.55872 0.105 0.9197
공부시간 0.48876 0.17719 2.758 0.0329 *
등급평균 7.37578 8.63161 0.855 0.4256
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.952 on 6 degrees of freedom
Multiple R-squared: 0.9155, Adjusted R-squared: 0.8733
F-statistic: 21.68 on 3 and 6 DF, p-value: 0.001275
> 공부시간만 유의미한 변수이고 아이큐와 등급평균 둘 다 유의미한 독립변수가 아님을 나타내고 있음. 둘다 p-value가 0.05보다 큰 값이 출력되었음. 즉 각각의 독립변수들이 종속변수에 유의한 영향을 미치지 못하고 있음. 그렇기 때문에 아이큐와 등급평균 둘 다 시험점수에 미치는 영향이 없거나 또는 두 변수의 다중 공선성을 의심해봐야함.
#9. 다중 공선성 여부를 확인
vif(model2) > 10 아이큐 공부시간 등급평균
TRUE FALSE TRUE
> 현업기준으로 봤을 때 아이큐와 등급평균이 둘 다 높은 다중공선성 여부를 보이므로 회귀분석 결과에 좋지 않은 영향을 미침. 이럴때 둘 중에 하나를 제외하고 회귀분석을 해야함. 그러면 둘 중에 어떤것을 제외시켜야 할지는 각각 테스트를 해보고 결정계수가 높은 것을 선택하면 됨.
model5 <- lm(시험점수 ~ 아이큐 + 공부시간, data = test2)
vif(model5) >10
summary(model5)
model6 <- lm(시험점수 ~ 등급평균 + 공부시간, data = test2)
vif(model6) > 10
summary(model6)
> 위와 같이 다중공선성 문제를 보이는 변수들을 따로 따로 돌려봤을 때는 대립가설을 채택할 충분한 근거가 있는 결과가 출력이 되었음.
ㅇ 파이썬으로 다중공선성 문제를 실험하는 방법
# python
#1. 데이터 로드
import pandas as pd
test2 = pd.read_csv("c:\\data\\test_vif2.csv", encoding = 'euckr')
test2 = test2.iloc[:,1:]
#2. 독립변수들끼리 상관관계 확인
test2.corr()> 아이큐와 시험점수와 아주 강한 양의 상관관계를 보이고 있음. 그래서 다중 회귀분석 결과에서도 아이큐가 유의미한 독립변수로 출력될 것을 기대할 수 있음. 그런데 아이큐와 등급평균이 거의 1에 가까운 아주 강한 양의 상관관계를 보이고 있어서 다중공선성 문제가 의심이 되는 상황
#3. 다중회귀 모델
from statsmodels.formula.api import ols
model = ols('시험점수 ~ 아이큐+공부시간+등급평균', test2)
result = model.fit() # 모델훈련
result.summary()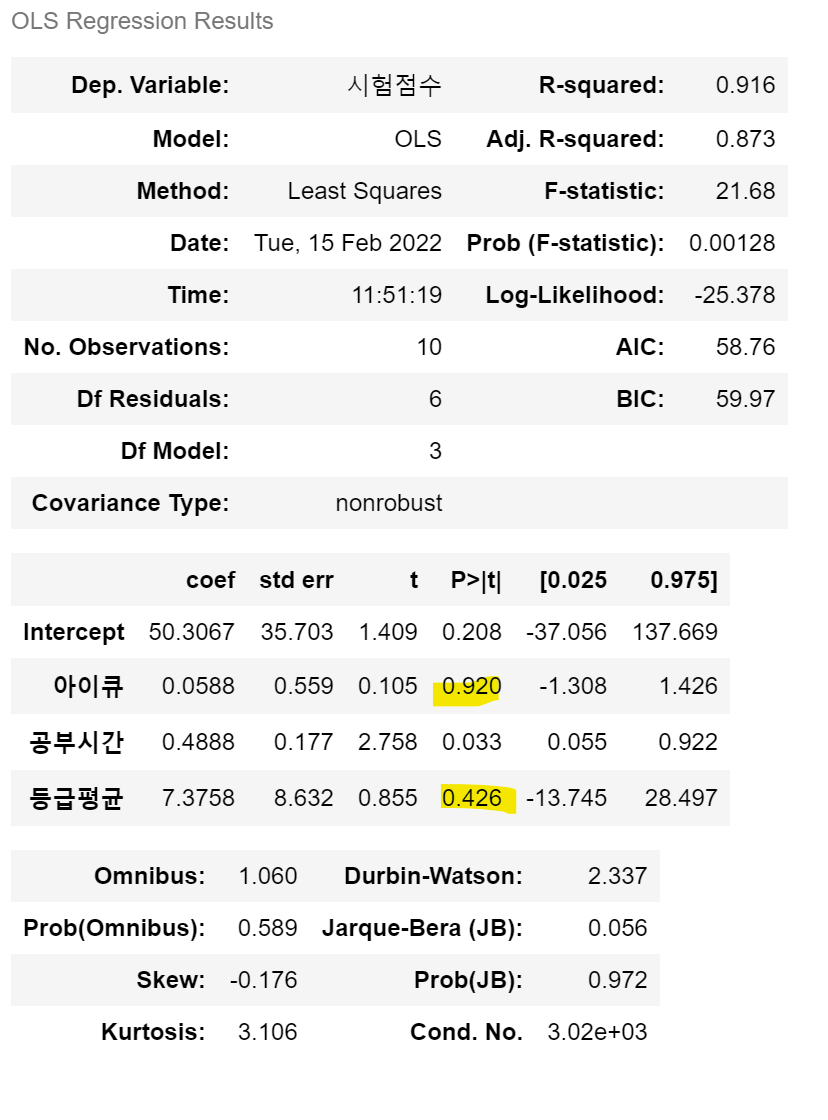
print('결정계수: ', result.rsquared)결정계수: 0.9155448852987763
> 상관관계 데이터 분석에서는 아이큐와 시험점수가 강한 양의 상관관계를 보여서 아이큐가 시험점수에 영향이 있을거라 예측했는데 다중회귀분석 결과에서는 아이큐가 시험점수에 영향이 없다라는 결과를 도출하고 있어서 다중공성선문제를 의심해봐야함.
#4. 다중공선성 확인을 위해 팽창계수 확인
from statsmodels.stats.outliers_influence import variance_inflation_factor
model.exog_names # 모델에서 보이는 컬럼명과 순서를 확인 ['Intercept', '아이큐', '공부시간', '등급평균']
print(variance_inflation_factor(model.exog,1)) #아이큐 22.64355276424414
print(variance_inflation_factor(model.exog,2)) #공부시간 2.5177862499212305
print(variance_inflation_factor(model.exog,3)) #등급평균 19.658263836145316> 아이큐와 등급평균의 팽창계수가 10보다 크게 출력되고 있어서 이 두개의 독립변수들이 유의미한 독립변수로 확인되고 있지 않는 것.
문제314. 등급평균과 공부시간을 독립변수로 하고 시험점수를 종속변수로 해서 다중회귀모델을 만들고 위의 결과에서는 등급평균이 시험점수에 영향을 주지 않는 유의미한 독립변수는 아니라고 나오는데 아이큐 빼고 따로 모델을 만들면 유의미한 독립변수가 되는지 확인하시오.
#1. 데이터로드
#2. 다중회귀 모델 생성
#3. 회귀분석결과 확인
#1. 데이터로드
import pandas as pd
test2 = pd.read_csv("c:\\data\\test_vif2.csv", encoding = 'euckr')
test2 = test2.iloc[:,1:]
test2.head()
#2. 다중회귀 모델 생성
from statsmodels.formula.api import ols
model = ols('시험점수 ~ 공부시간+등급평균', test2)
result = model.fit() # 모델훈련
result.summary()
#3. 회귀분석결과 확인
> 등급평균의 p-value가 0.017로 유의수준을 0.05로 했을 때 대립가설을 채택할 충분한 근거가 있음.
문제315. (점심시간 문제) 등급평균과 아이큐를 독립변수로 하고 시험점수를 종속변수로 해서 다중회귀 모델을 만들고 위의 결과에서는 아이큐가 시험점수에 영향을 주지 않는 유의미한 독립변수는 아니라고 나오는데 등급평균을 빼고 따로 모델을 만들면 아이큐가 유의미한 독립변수가 되는지 확인하시오.
#1. 데이터로드
import pandas as pd
test2 = pd.read_csv("c:\\data\\test_vif2.csv", encoding = 'euckr')
test2 = test2.iloc[:,1:]
test2.head()
#2. 다중회귀 모델 생성
from statsmodels.formula.api import ols
model = ols('시험점수 ~ 아이큐+공부시간', test2)
result = model.fit() # 모델훈련
result.summary()
#3. 회귀분석결과 확인
> 아이큐의 p-value가 0.026으로 유의수준을 0.05로 했을 때 대립가설을 채택할 충분한 근거가 있음.
59 다중회귀분석 모델을 파이썬을 구현
목표 : "미국민의 의료비를 예측하는 회귀모델 생성"
데이터셋 : insurance.csv
종속변수 : expenses
독립변수 : age, sex, bmi, children, smoker, region
#1. 데이터 로드
#2. 결측치 확인
#3. 종속변수 데이터가 정규분포형태를 보이는지 확인
#4. 상관관계 분석
#5. 다중 회귀 모델을 생성
#6. 모델 훈련
#7. 분석 결과 확인
#1. 데이터 로드
insurance = pd.read_csv("c:\\data\\insurance.csv")
insurance.head()
insurance.count() #1338
insurance.shape #(1338, 7)
#2. 결측치 확인
insurance.isnull().sum() # 결측치 없음 확인
#3. 종속변수 데이터가 정규분포형태를 보이는지 확인
import seaborn as sns
import matplotlib.pyplot as plt
sns.distplot(insurance.expenses, bins = 20)
plt.rc('font',family = 'Malgun Gothic') # 한글 안깨지게 하는 코드
plt.show()
#4. 상관관계 분석
insurance.corr()
> 나이가 들수록 의료비가 많이 들고 나이가 들수록 비만지수가 올라간다는 것을 상관관계 데이터 분석으로 확인함.
#5. 다중 회귀 모델을 생성
import statsmodels.formula.api as smf
model = smf.ols(formula = 'expenses ~ age+sex+bmi+children+smoker+region', data = insurance)
#6. 모델 훈련
result = model.fit()
result.params #기울기만 보고 싶을 때Intercept -11941.562461
sex[T.male] -131.352014 -> 남성은 여성에 비해 매년 의료비가 131달러 적게 들거라 예상
smoker[T.yes] 23847.476695 -> 흡연자는 비흡연자보다 매년 의료비가 23,847달러 더 비용이 들거라 예상
region[T.northwest] -352.790096 -> northwest 거주자는 northeast 거주자에 비해 의료비가 352달러 적게 듦.
region[T.southeast] -1035.595701 -> southeast 거주자는 northeast 거주자에 비해 의료비가 1035달러 적게 듦.
region[T.southwest] -959.305829 -> southwest 거주자는 northeast 거주자에 비해 의료비가 959달러 적게 듦.
age 256.839171 -> 나이가 한 살 늘때마다 평균적으로 의료비가 256달러 더 듦.
bmi 339.289863 -> 비만지수가 1 증가할 때마다 의료비가 339달러 더 듦.
children 475.688916 -> 부양가족이 1명 늘어날 때마다 연간의료비가 475달러 더 듦.
result.summary()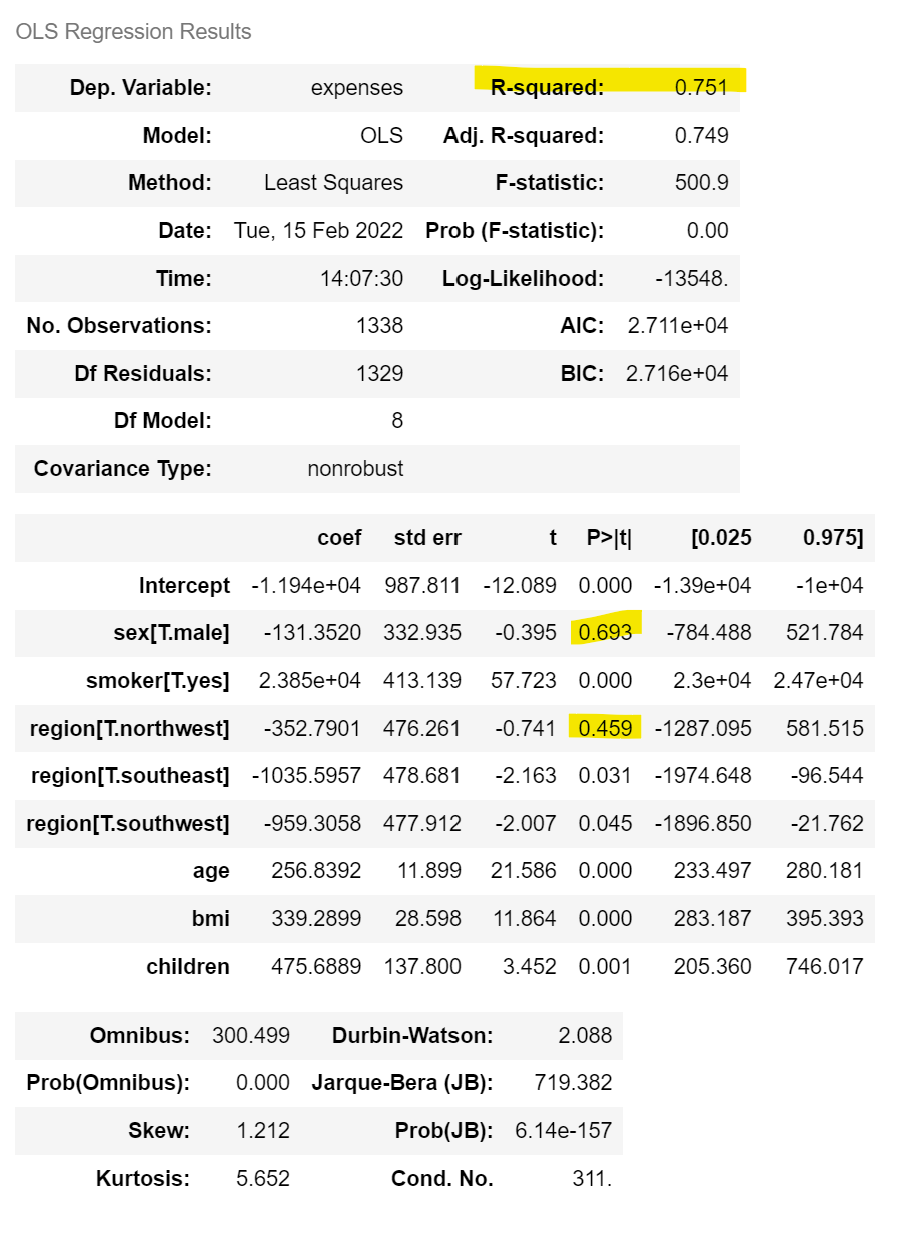
문제316. 비만인 사람이 의료비가 더 지출되는지 확인하기 위하여 bmi30이라는 파생변수를 생성하여 insurance에 추가하시오.
# bmi30 파생변수 추가
insurance['bmi30'] = list(map(lambda x: 1 if x>= 30 else 0,insurance['bmi']))
insurance.head()문제317. 이번에는 모델을 model2로 생성하는데 위에 만든 bmi30 파생변수까지 추가해서 모델을 만들고 결정계수가 올라가는지 확인하시오.
#5. 다중 회귀 모델을 생성
import statsmodels.formula.api as smf
model2 = smf.ols(formula = 'expenses ~ age+sex+bmi+bmi30+children+smoker+region', data = insurance)
#6. 모델 훈련
result = model2.fit()
result.params #기울기만 보고 싶을 때
result.summary()
#7. 분석 결과 확인
> 결정계수가 0.751에서 0.756으로 결정계수가 올라감
> 비만은 의료비 상승에 연관성이 있다는 것이 확인됨
bmi30에 대한 p-value값은 0.000
문제318. 비만이면서 흡연까지 하게 되면 의료비가 상승하는지 보기 위해서 bmi30이 1이면서 smoker가 yes이면 1이라고 하고 아니면 0이라고 하는 bmi30_smoker라는 파생변수를 추가하시오.
# bmi30_smoker 파생변수 추가
insurance['bmi30_smoker'] = list(map((lambda x,y : 1 if x>=1 and y == 'yes' else 0), insurance['bmi30'],insurance['smoker']))
# 다른사람이 푼 코드
insurance['bmi30_smoker2'] = ((insurance['bmi30']>= 1) & (insurance['smoker'] == 'yes')).apply(lambda x: 1 if x == True else 0)문제319. 이번에는 model3을 생성하는데 bmi30_smoker를 추가해서 model3을 생성하고 훈련시킨 후에 결정계수가 올라가는지 확인하시오.
# bmi30_smoke파생변수 추가
insurance['bmi30_smoker'] = list(map((lambda x,y : 1 if x>=1 and y == 'yes' else 0), insurance['bmi30'],insurance['smoker']))
insurance.head()
#5. 다중 회귀 모델을 생성
import statsmodels.formula.api as smf
model3 = smf.ols(formula = 'expenses ~ age+sex+bmi+bmi30+bmi30_smoker+smoker+children+region', data = insurance)
#6. 모델 훈련
result = model3.fit()
result.params #기울기만 보고 싶을 때
result.summary()
#7. 분석 결과 확인
> 결정계수가 0.864로 올라갔음.
문제320. 파이썬으로 다중회귀모델을 생성하는데 우주왕복선 데이터의 o형링 파손에 영향을 미치는 독립변수들 온도, 압력, 비행기 번호중에 어떤게 가장 영향이 큰지를 확인하는 다중회귀모델을 생성하시오.
귀무가설 : 온도와 o형링 파손은 관련이 없다, 압력과 o형링 파손은 관련이 없다, 비행기번호는 o형링 파손은 관련이 없다.
대립가설 : 온도와 o형링 파손은 관련이 있다, 압력과 o형링 파손은 관련이 있다, 비행기번호는 o형링 파손은 관련이 있다.
#1. 데이터 로드
import pandas as pd
cha = pd.read_csv("c:\\data\\challenger.csv")
cha.head()
cha.shape #(23, 4)
#2. 결측치 확인
cha.isnull().sum() # 결측치 없음
#3. 상관관계 확인
cha.corr()
# 이미지로 상관관계 확인하고 싶은 경우
# import pandas as pd
# import seaborn as sns
# import matplotlib.pyplot as plt
# sns.heatmap(cha.corr(), annot = True, cmap = 'GnBu', linewidths = 0.2)
# fig = plt.gcf() # fig를 지정하고 나서
# fig.set_size_inches(10,8) # 그래프의 사이즈 조절
# plt.show()
#4. 다중회귀모델을 생성
import statsmodels.formula.api as smf
model = smf.ols('distress_ct ~ temperature + field_check_pressure + flight_num', data = cha)
#5. 모델 훈련
result = model.fit()
#6. 다중공선성 문제 확인
from statsmodels.stats.outliers_influence import variance_inflation_factor
model.exog_names # 컬럼명 확인
for i in range(1,len(model.exog_names)):
print(model.exog_names[i], variance_inflation_factor(model.exog, i))
#7. 다중회귀모델 결과 분석
result.summary()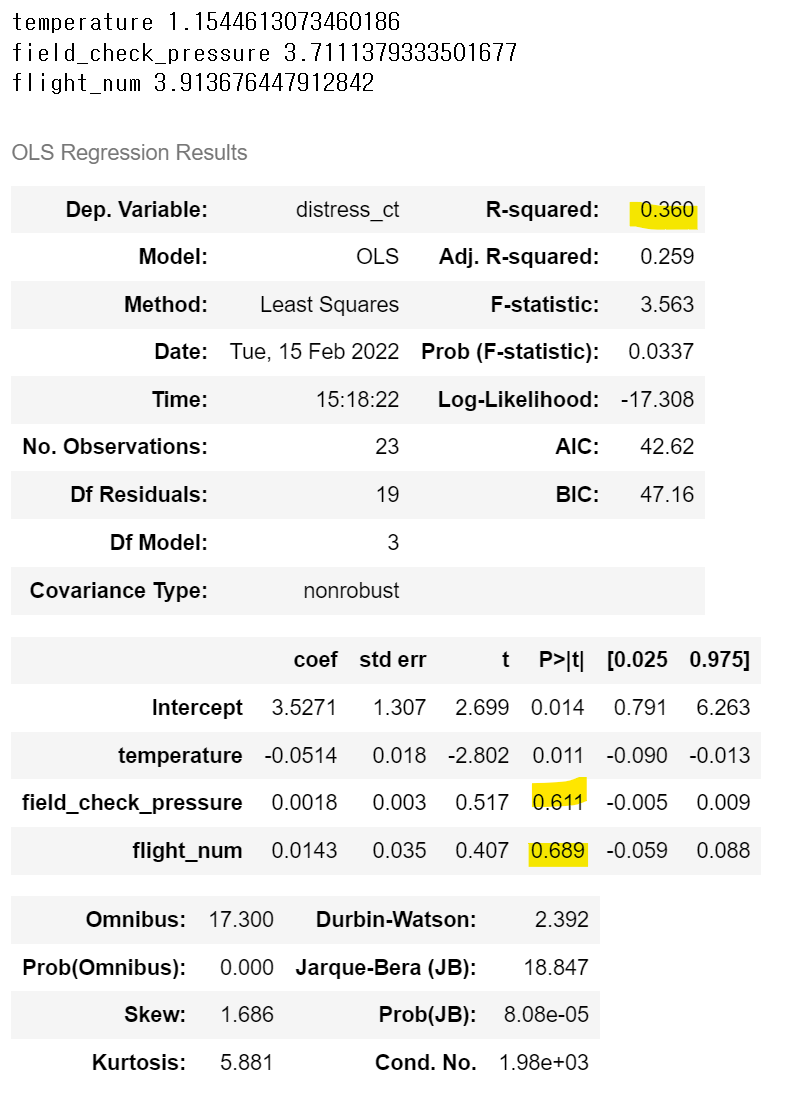
> 팽창계수의 기준을 10으로 하게 되면 다중공선성 문제를 보이는 독립변수들은 없음.
> 온도의 p-value가 0.011로 유의수준 0.05보다 작으므로 귀무가설은 기각되고 대립가설 채택. 온도가 o형링 파손에 관계가 있다는 충분한 근거가 있음.
> 압력과 비행기 번호는 귀무가설을 기각할 수 없음.
result.paramsIntercept 3.527093
temperature -0.051386
field_check_pressure 0.001757
flight_num 0.014293
> o형링 파손수 = 3.5271 - 0.0514 * 온도
2.21개 화씨 30도
0.82개 화씨 60도
0.34개 화씨 70도
30도에서 발사하는 것이 60도에서 발사하는 것보다 3배 더 위험하고 70도에서 발사하는 것보다 7~8배 더 위험함.
+) 다중회귀분석 파이썬 전체코드
#1. 데이터 로드
import pandas as pd
cha = pd.read_csv("c:\\data\\challenger.csv")
cha.head()
cha.shape #(23, 4)
#2. 결측치 확인
cha.isnull().sum() # 결측치 없음
#3. 상관관계 확인
cha.corr()
# 이미지로 상관관계 확인하고 싶은 경우
# import pandas as pd
# import seaborn as sns
# import matplotlib.pyplot as plt
# sns.heatmap(cha.corr(), annot = True, cmap = 'GnBu', linewidths = 0.2)
# fig = plt.gcf() # fig를 지정하고 나서
# fig.set_size_inches(10,8) # 그래프의 사이즈 조절
# plt.show()
#4. 다중회귀모델을 생성
import statsmodels.formula.api as smf
model = smf.ols('distress_ct ~ temperature + field_check_pressure + flight_num', data = cha)
#5. 모델 훈련
result = model.fit()
#6. 다중공선성 문제 확인
from statsmodels.stats.outliers_influence import variance_inflation_factor
model.exog_names # 컬럼명 확인
for i in range(1,len(model.exog_names)):
print(model.exog_names[i], variance_inflation_factor(model.exog, i))
#7. 다중회귀모델 결과 분석
result.summary()
# 회귀계수
print(result.params)
'Study > class note' 카테고리의 다른 글
| 머신러닝 / R 로 회귀트리 구현하기, R 로 모델트리 구현하기 (0) | 2022.02.16 |
|---|---|
| 머신러닝 / 회귀트리 (0) | 2022.02.15 |
| 머신러닝 / 다중회귀분석 모델을 R 로 구현 (0) | 2022.02.14 |
| 머신러닝 / 다중 회귀분석 이론 (0) | 2022.02.11 |
| 머신러닝 / 다중 공선성, 상관관계 분석, 단순회귀분석 모델 구현(R, 파이썬) (0) | 2022.02.11 |



